
Prospects throughout all industries are experimenting with generative AI to speed up and enhance enterprise outcomes. Generative AI is utilized in varied use circumstances, resembling content material creation, personalization, clever assistants, questions and solutions, summarization, automation, cost-efficiencies, productiveness enchancment assistants, customization, innovation, and extra.



Generative AI options usually use Retrieval Augmented Technology (RAG) architectures, which increase exterior information sources for enhancing content material high quality, context understanding, creativity, domain-adaptability, personalization, transparency, and explainability.
This publish dives deep into Amazon Bedrock Information Bases, which helps with the storage and retrieval of knowledge in vector databases for RAG-based workflows, with the target to enhance massive language mannequin (LLM) responses for inference involving a company’s datasets.
Advantages of vector information shops
A number of challenges come up when dealing with complicated eventualities coping with information like information volumes, multi-dimensionality, multi-modality, and different interfacing complexities. For instance:
- Information resembling photos, textual content, and audio must be represented in a structured and environment friendly method
- Understanding the semantic similarity between information factors is important in generative AI duties like pure language processing (NLP), picture recognition, and suggestion programs
- As the amount of knowledge continues to develop quickly, scalability turns into a big problem
- Conventional databases might wrestle to effectively deal with the computational calls for of generative AI duties, resembling coaching complicated fashions or performing inference on massive datasets
- Generative AI purposes incessantly require looking out and retrieving comparable objects or patterns inside datasets, resembling discovering comparable photos or recommending related content material
- Generative AI options usually contain integrating a number of elements and applied sciences, resembling deep studying frameworks, information processing pipelines, and deployment environments
Vector databases function a basis in addressing these information wants for generative AI options, enabling environment friendly illustration, semantic understanding, scalability, interoperability, search and retrieval, and mannequin deployment. They contribute to the effectiveness and feasibility of generative AI purposes throughout varied domains. Vector databases supply the next capabilities:
- Present a method to symbolize information in a structured and environment friendly method, enabling computational processing and manipulation
- Allow the measurement of semantic similarity by encoding information into vector representations, permitting for comparability and evaluation
- Deal with large-scale datasets effectively, enabling processing and evaluation of huge quantities of knowledge in a scalable method
- Present a standard interface for storing and accessing information representations, facilitating interoperability between totally different elements of the AI system
- Assist environment friendly search and retrieval operations, enabling fast and correct exploration of enormous datasets
To assist implement generative AI-based purposes securely at scale, AWS offers Amazon Bedrock, a completely managed service that allows deploying generative AI purposes that use high-performing LLMs from main AI startups and Amazon. With the Amazon Bedrock serverless expertise, you’ll be able to experiment with and consider high basis fashions (FMs) to your use circumstances, privately customise them together with your information utilizing methods resembling fine-tuning and RAG, and construct brokers that run duties utilizing enterprise programs and information sources.
On this publish, we dive deep into the vector database choices out there as a part of Amazon Bedrock Information Bases and the relevant use circumstances, and take a look at working code examples. Amazon Bedrock Information Bases permits quicker time to market by abstracting from the heavy lifting of constructing pipelines and offering you with an out-of-the-box RAG resolution to scale back the construct time to your utility.
Information base programs with RAG
RAG optimizes LLM responses by referencing authoritative information bases outdoors of its coaching information sources earlier than producing a response. Out of the field, LLMs are educated on huge volumes of knowledge and use billions of parameters to generate authentic output for duties like answering questions, translating languages, and finishing sentences. RAG extends the prevailing highly effective capabilities of LLMs to particular domains or a company’s inside information base, all with out the necessity to retrain the mannequin. It’s an economical method to enhancing an LLM’s output so it stays related, correct, and helpful in varied contexts.
The next diagram depicts the high-level steps of a RAG course of to entry a company’s inside or exterior information shops and move the info to the LLM.
The workflow consists of the next steps:
- Both a consumer by way of a chatbot UI or an automatic course of points a immediate and requests a response from the LLM-based utility.
- An LLM-powered agent, which is chargeable for orchestrating steps to answer the request, checks if further data is required from information sources.
- The agent decides which information supply to make use of.
- The agent invokes the method to retrieve data from the information supply.
- The related data (enhanced context) from the information supply is returned to the agent.
- The agent provides the improved context from the information supply to the immediate and passes it to the LLM endpoint for the response.
- The LLM response is handed again to the agent.
- The agent returns the LLM response to the chatbot UI or the automated course of.
Use circumstances for vector databases for RAG
Within the context of RAG architectures, the exterior information can come from relational databases, search and doc shops, or different information shops. Nevertheless, merely storing and looking out by way of this exterior information utilizing conventional strategies (resembling key phrase search or inverted indexes) will be inefficient and won’t seize the true semantic relationships between information factors. Vector databases are advisable for RAG use circumstances as a result of they allow similarity search and dense vector representations.
The next are some eventualities the place loading information right into a vector database will be advantageous for RAG use circumstances:
- Giant information bases – When coping with intensive information bases containing tens of millions or billions of paperwork or passages, vector databases can present environment friendly similarity search capabilities.
- Unstructured or semi-structured information – Vector databases are notably well-suited for dealing with unstructured or semi-structured information, resembling textual content paperwork, webpages, or pure language content material. By changing the textual information into dense vector representations, vector databases can successfully seize the semantic relationships between paperwork or passages, enabling extra correct retrieval.
- Multilingual information bases – In RAG programs that have to deal with information bases spanning a number of languages, vector databases will be advantageous. By utilizing multilingual language fashions or cross-lingual embeddings, vector databases can facilitate efficient retrieval throughout totally different languages, enabling cross-lingual information switch.
- Semantic search and relevance rating – Vector databases excel at semantic search and relevance rating duties. By representing paperwork or passages as dense vectors, the retrieval element can use vector similarity measures to determine probably the most semantically related content material.
- Personalised and context-aware retrieval – Vector databases can help personalised and context-aware retrieval in RAG programs. By incorporating consumer profiles, preferences, or contextual data into the vector representations, the retrieval element can prioritize and floor probably the most related content material for a particular consumer or context.
Though vector databases supply benefits in these eventualities, their implementation and effectiveness might depend upon components resembling the particular vector embedding methods used, the standard and illustration of the info, and the computational assets out there for indexing and retrieval operations. With Amazon Bedrock Information Bases, you may give FMs and brokers contextual data out of your firm’s non-public information sources for RAG to ship extra related, correct, and customised responses.
Amazon Bedrock Information Bases with RAG
Amazon Bedrock Information Bases is a completely managed functionality that helps with the implementation of your complete RAG workflow, from ingestion to retrieval and immediate augmentation, with out having to construct customized integrations to information sources and handle information flows. Information bases are important for varied use circumstances, resembling buyer help, product documentation, inside information sharing, and decision-making programs. A RAG workflow with information bases has two predominant steps: information preprocessing and runtime execution.
The next diagram illustrates the info preprocessing workflow.
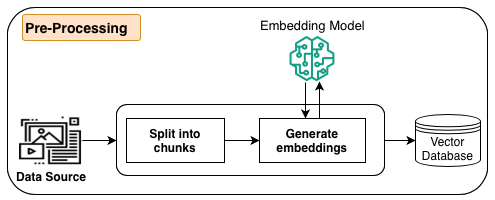
As a part of preprocessing, data (structured information, unstructured information, or paperwork) from information sources is first break up into manageable chunks. The chunks are transformed to embeddings utilizing embeddings fashions out there in Amazon Bedrock. Lastly, the embeddings are written right into a vector database index whereas sustaining a mapping to the unique doc. These embeddings are used to find out semantic similarity between queries and textual content from the info sources. All these steps are managed by Amazon Bedrock.
The next diagram illustrates the workflow for the runtime execution.
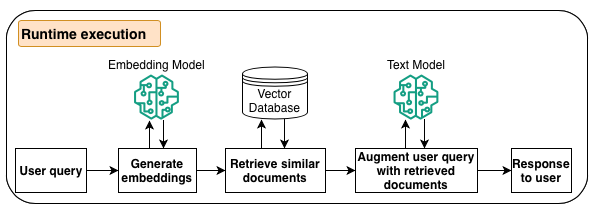
In the course of the inference part of the LLM, when the agent determines that it wants further data, it reaches out to information bases. The method converts the consumer question into vector embeddings utilizing an Amazon Bedrock embeddings mannequin, queries the vector database index to seek out semantically comparable chunks to the consumer’s question, converts the retrieved chunks to textual content and augments the consumer question, after which responds again to the agent.
Embeddings fashions are wanted within the preprocessing part to retailer information in vector databases and in the course of the runtime execution part to generate embeddings for the consumer question to look the vector database index. Embeddings fashions map high-dimensional and sparse information like textual content into dense vector representations to be effectively saved and processed by vector databases, and encode the semantic which means and relationships of knowledge into the vector house to allow significant similarity searches. These fashions help mapping totally different information sorts like textual content, photos, audio, and video into the identical vector house to allow multi-modal queries and evaluation. Amazon Bedrock Information Bases offers industry-leading embeddings fashions to allow use circumstances resembling semantic search, RAG, classification, and clustering, to call just a few, and offers multilingual help as properly.
Vector database choices with Amazon Bedrock Information Bases
On the time of scripting this publish, Amazon Bedrock Information Bases offers 5 integration choices: the Vector Engine for Amazon OpenSearch Serverless, Amazon Aurora, MongoDB Atlas, Pinecone, and Redis Enterprise Cloud, with extra vector database choices to come back. On this publish, we talk about use circumstances, options, and steps to arrange and retrieve data utilizing these vector databases. Amazon Bedrock makes it easy to undertake any of those decisions by offering a standard set of APIs, industry-leading embedding fashions, safety, governance, and observability.
Function of metadata whereas indexing information in vector databases
Metadata performs an important position when loading paperwork right into a vector information retailer in Amazon Bedrock. It offers further context and details about the paperwork, which can be utilized for varied functions, resembling filtering, sorting, and enhancing search capabilities.
The next are some key makes use of of metadata when loading paperwork right into a vector information retailer:
- Doc identification – Metadata can embody distinctive identifiers for every doc, resembling doc IDs, URLs, or file names. These identifiers can be utilized to uniquely reference and retrieve particular paperwork from the vector information retailer.
- Content material categorization – Metadata can present details about the content material or class of a doc, resembling the subject material, area, or subject. This data can be utilized to prepare and filter paperwork based mostly on particular classes or domains.
- Doc attributes – Metadata can retailer further attributes associated to the doc, such because the writer, publication date, language, or different related data. These attributes can be utilized for filtering, sorting, or faceted search inside the vector information retailer.
- Entry management – Metadata can embody details about entry permissions or safety ranges related to a doc. This data can be utilized to regulate entry to delicate or restricted paperwork inside the vector information retailer.
- Relevance scoring – Metadata can be utilized to boost the relevance scoring of search outcomes. For instance, if a consumer searches for paperwork inside a particular date vary or authored by a selected particular person, the metadata can be utilized to prioritize and rank probably the most related paperwork.
- Information enrichment – Metadata can be utilized to counterpoint the vector representations of paperwork by incorporating further contextual data. This could probably enhance the accuracy and high quality of search outcomes.
- Information lineage and auditing – Metadata can present details about the provenance and lineage of paperwork, such because the supply system, information ingestion pipeline, or different transformations utilized to the info. This data will be useful for information governance, auditing, and compliance functions.
Stipulations
Full the steps on this part to arrange the prerequisite assets and configurations.
Configure Amazon SageMaker Studio
Step one is to arrange an Amazon SageMaker Studio pocket book to run the code for this publish. You’ll be able to arrange the pocket book in any AWS Area the place Amazon Bedrock Information Bases is out there.
- Full the conditions to arrange Amazon SageMaker.
- Full the fast setup or customized setup to allow your SageMaker Studio area and consumer profile.
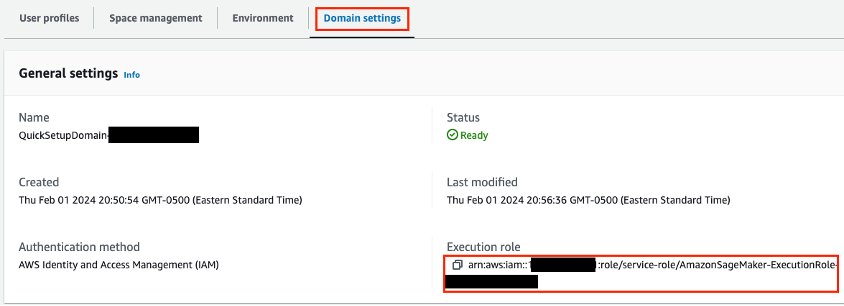
You additionally want an AWS Id and Entry Administration (IAM) position assigned to the SageMaker Studio area. You’ll be able to determine the position on the SageMaker console. On the Domains web page, open your area. The IAM position ARN is listed on the Area settings tab.
The position wants permissions for IAM, Amazon Relational Database Service (Amazon RDS), Amazon Bedrock, AWS Secrets and techniques Supervisor, Amazon Easy Storage Service (Amazon S3), and Amazon OpenSearch Serverless. - Modify the position permissions so as to add the next insurance policies:
IAMFullAccessAmazonRDSFullAccessAmazonBedrockFullAccessSecretsManagerReadWriteAmazonRDSDataFullAccessAmazonS3FullAccess- The next inline coverage:
- On the SageMaker console, select Studio within the navigation pane.
- Select your consumer profile and select Open Studio.

This may open a brand new browser tab for SageMaker Studio Basic.
- Run the SageMaker Studio utility.

- When the applying is operating, select Open.

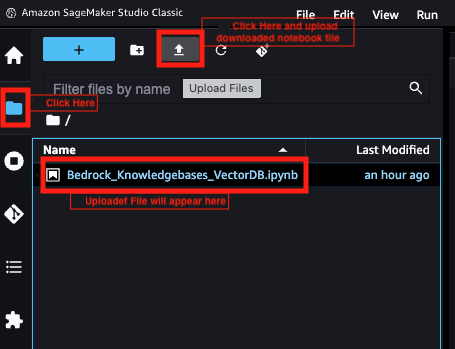
JupyterLab will open in a brand new tab. - Obtain the pocket book file to make use of on this publish.
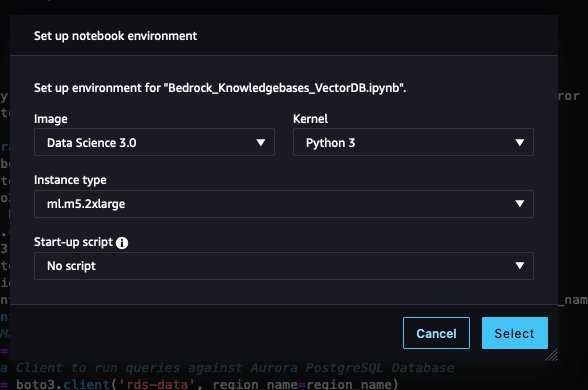
- Select the file icon within the navigation pane, then select the add icon, and add the pocket book file.

- Depart the picture, kernel, and occasion sort as default and select Choose.





Request Amazon Bedrock mannequin entry
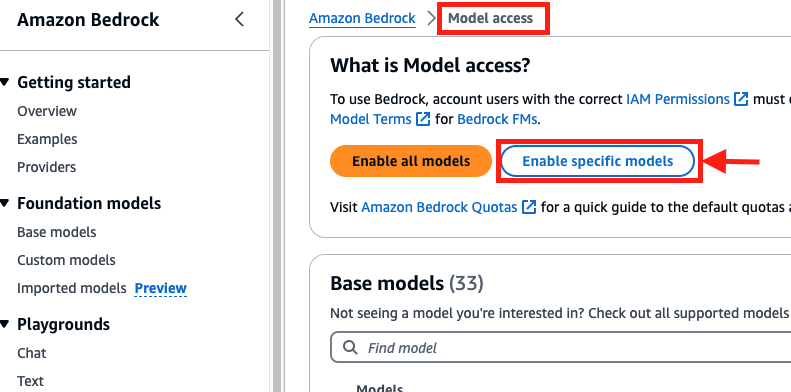
Full the next steps to request entry to the embeddings mannequin in Amazon Bedrock:
- On the Amazon Bedrock console, select Mannequin entry within the navigation pane.
- Select Allow particular fashions.
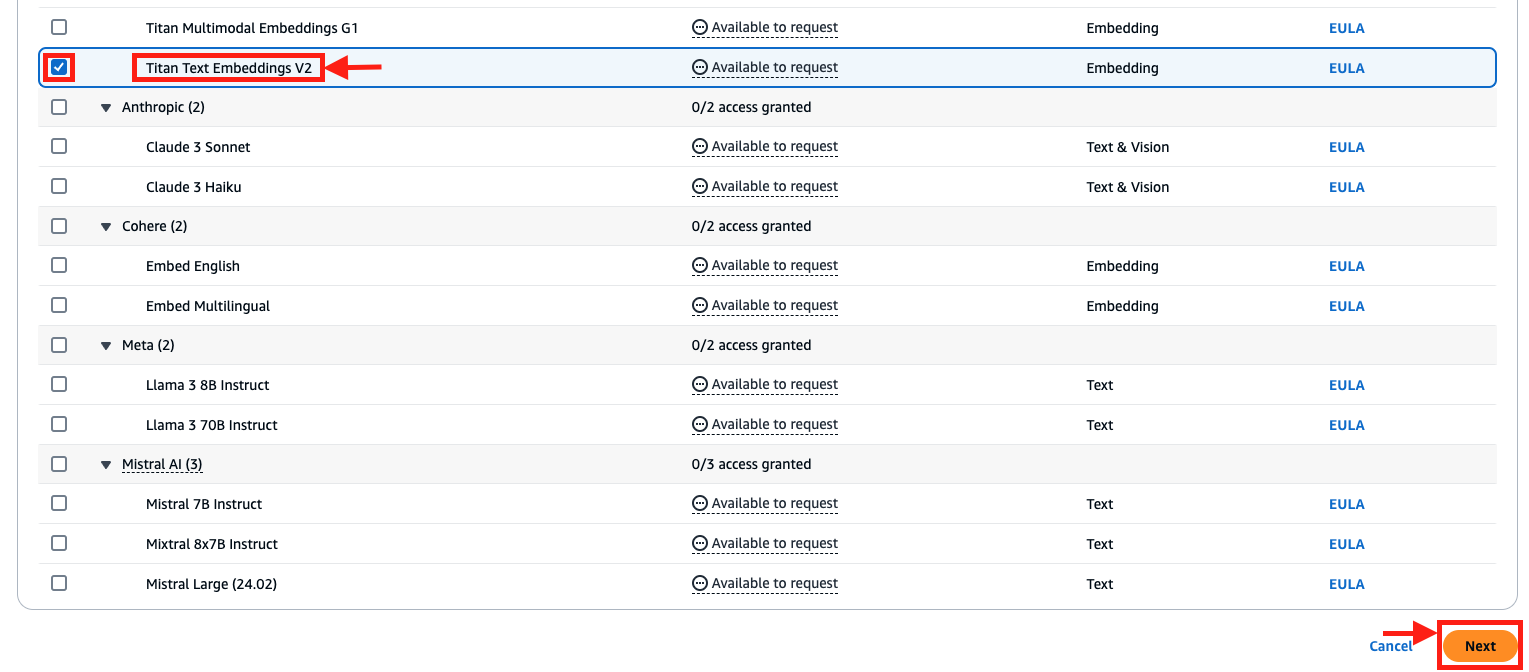
- Choose the Titan Textual content Embeddings V2 mannequin.
- Select Subsequent and full the entry request.


Import dependencies
Open the pocket book file Bedrock_Knowledgebases_VectorDB.ipynb and run Step 1 to import dependencies for this publish and create Boto3 purchasers:
Create an S3 bucket
You need to use the next code to create an S3 bucket to retailer the supply information to your vector database, or use an current bucket. When you create a brand new bucket, make sure that to comply with your group’s finest practices and tips.
Arrange pattern information
Use the next code to arrange the pattern information for this publish, which would be the enter for the vector database:
Configure the IAM position for Amazon Bedrock
Use the next code to outline the perform to create the IAM position for Amazon Bedrock, and the features to connect insurance policies associated to Amazon OpenSearch Service and Aurora:
Use the next code to create the IAM position for Amazon Bedrock, which you’ll use whereas creating the information base:
Combine with OpenSearch Serverless
The Vector Engine for Amazon OpenSearch Serverless is an on-demand serverless configuration for OpenSearch Service. As a result of it’s serverless, it removes the operational complexities of provisioning, configuring, and tuning your OpenSearch clusters. With OpenSearch Serverless, you’ll be able to search and analyze a big quantity of knowledge with out having to fret concerning the underlying infrastructure and information administration.
The next diagram illustrates the OpenSearch Serverless structure. OpenSearch Serverless compute capability for information ingestion, looking out, and querying is measured in OpenSearch Compute Items (OCUs).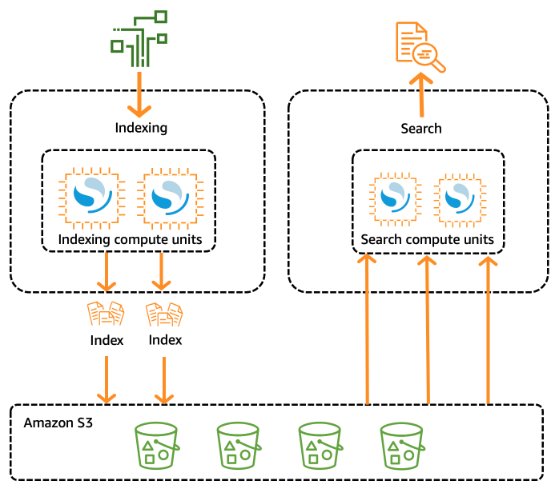
The vector search assortment sort in OpenSearch Serverless offers a similarity search functionality that’s scalable and excessive performing. This makes it a well-liked possibility for a vector database when utilizing Amazon Bedrock Information Bases, as a result of it makes it easy to construct trendy machine studying (ML) augmented search experiences and generative AI purposes with out having to handle the underlying vector database infrastructure. Use circumstances for OpenSearch Serverless vector search collections embody picture searches, doc searches, music retrieval, product suggestions, video searches, location-based searches, fraud detection, and anomaly detection. The vector engine offers distance metrics resembling Euclidean distance, cosine similarity, and dot product similarity. You’ll be able to retailer fields with varied information sorts for metadata, resembling numbers, Booleans, dates, key phrases, and geopoints. You can even retailer fields with textual content for descriptive data so as to add extra context to saved vectors. Collocating the info sorts reduces complexity, will increase maintainability, and avoids information duplication, model compatibility challenges, and licensing points.
The next code snippets arrange an OpenSearch Serverless vector database and combine it with a information base in Amazon Bedrock:
- Create an OpenSearch Serverless vector assortment.
- Create an index within the assortment; this index shall be managed by Amazon Bedrock Information Bases:
- Create a information base in Amazon Bedrock pointing to the OpenSearch Serverless vector assortment and index:
- Create an information supply for the information base:
- Begin an ingestion job for the information base pointing to OpenSearch Serverless to generate vector embeddings for information in Amazon S3:
Combine with Aurora pgvector
Aurora offers pgvector integration, which is an open supply extension for PostgreSQL that provides the power to retailer and search over ML-generated vector embeddings. This allows you to use Aurora for generative AI RAG-based use circumstances by storing vectors with the remainder of the info. The next diagram illustrates the pattern structure.
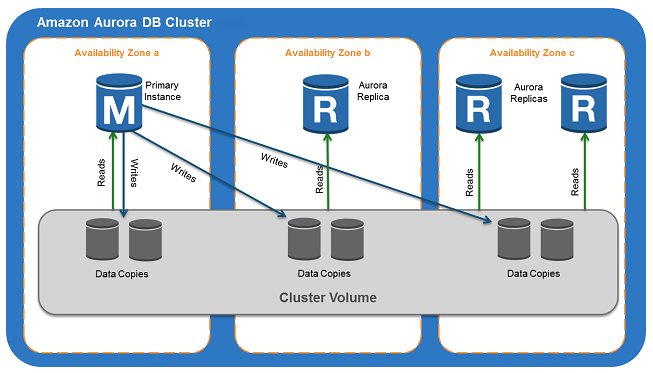
Use circumstances for Aurora pgvector embody purposes which have necessities for ACID compliance, point-in-time restoration, joins, and extra. The next is a pattern code snippet to configure Aurora together with your information base in Amazon Bedrock:
- Create an Aurora DB occasion (this code creates a managed DB occasion, however you’ll be able to create a serverless occasion as properly). Establish the safety group ID and subnet IDs to your VPC earlier than operating the next step and supply the suitable values within the
vpc_security_group_idsand SubnetIds variables: - On the Amazon RDS console, verify the Aurora database standing reveals as Accessible.

- Create the vector extension, schema, and vector desk within the Aurora database:
- Create a information base in Amazon Bedrock pointing to the Aurora database and desk:
- Create an information supply for the information base:
- Begin an ingestion job to your information base pointing to the Aurora pgvector desk to generate vector embeddings for information in Amazon S3:
Combine with MongoDB Atlas
MongoDB Atlas Vector Search, when built-in with Amazon Bedrock, can function a sturdy and scalable information base to construct generative AI purposes and implement RAG workflows. By utilizing the versatile doc information mannequin of MongoDB Atlas, organizations can symbolize and question complicated information entities and their relationships inside Amazon Bedrock. The mix of MongoDB Atlas and Amazon Bedrock offers a robust resolution for constructing and sustaining a centralized information repository.
To make use of MongoDB, you’ll be able to create a cluster and vector search index. The native vector search capabilities embedded in an operational database simplify constructing subtle RAG implementations. MongoDB means that you can retailer, index, and question vector embeddings of your information with out the necessity for a separate bolt-on vector database.
There are three pricing choices out there for MongoDB Atlas by way of AWS Market: MongoDB Atlas (pay-as-you-go), MongoDB Atlas Enterprise, and MongoDB Atlas for Authorities. Consult with the MongoDB Atlas Vector Search documentation to arrange a MongoDB vector database and add it to your information base.
Combine with Pinecone
Pinecone is a kind of vector database from Pinecone Techniques Inc. With Amazon Bedrock Information Bases, you’ll be able to combine your enterprise information into Amazon Bedrock utilizing Pinecone because the totally managed vector database to construct generative AI purposes. Pinecone is very performant; it might velocity by way of information in milliseconds. You need to use its metadata filters and sparse-dense index help for top-notch relevance, reaching fast, correct, and grounded outcomes throughout numerous search duties. Pinecone is enterprise prepared; you’ll be able to launch and scale your AI resolution with no need to keep up infrastructure, monitor companies, or troubleshoot algorithms. Pinecone adheres to the safety and operational necessities of enterprises.
There are two pricing choices out there for Pinecone in AWS Market: Pinecone Vector Database – Pay As You Go Pricing (serverless) and Pinecone Vector Database – Annual Commit (managed). Consult with the Pinecone documentation to arrange a Pinecone vector database and add it to your information base.
Combine with Redis Enterprise Cloud
Redis Enterprise Cloud allows you to arrange, handle, and scale a distributed in-memory information retailer or cache atmosphere within the cloud to assist purposes meet low latency necessities. Vector search is likely one of the resolution choices out there in Redis Enterprise Cloud, which solves for low latency use circumstances associated to RAG, semantic caching, doc search, and extra. Amazon Bedrock natively integrates with Redis Enterprise Cloud vector search.
There are two pricing choices out there for Redis Enterprise Cloud by way of AWS Market: Redis Cloud Pay As You Go Pricing and Redis Cloud – Annual Commits. Consult with the Redis Enterprise Cloud documentation to arrange vector search and add it to your information base.
Work together with Amazon Bedrock information bases
Amazon Bedrock offers a standard set of APIs to work together with information bases:
- Retrieve API – Queries the information base and retrieves data from it. It is a Bedrock Information Base particular API, it helps with use circumstances the place solely vector-based looking out of paperwork is required with out mannequin inferences.
- Retrieve and Generate API – Queries the information base and makes use of an LLM to generate responses based mostly on the retrieved outcomes.
The next code snippets present learn how to use the Retrieve API from the OpenSearch Serverless vector database’s index and the Aurora pgvector desk:
- Retrieve information from the OpenSearch Serverless vector database’s index:
- Retrieve information from the Aurora pgvector desk:
Clear up
If you’re carried out with this resolution, clear up the assets you created:
- Amazon Bedrock information bases for OpenSearch Serverless and Aurora
- OpenSearch Serverless assortment
- Aurora DB occasion
- S3 bucket
- SageMaker Studio area
- Amazon Bedrock service position
- SageMaker Studio area position
Conclusion
On this publish, we offered a high-level introduction to generative AI use circumstances and using RAG workflows to enhance your group’s inside or exterior information shops. We mentioned the significance of vector databases and RAG architectures to allow similarity search and why dense vector representations are useful. We additionally went over Amazon Bedrock Information Bases, which offers widespread APIs, industry-leading governance, observability, and safety to allow vector databases utilizing totally different choices like AWS native and associate merchandise by way of AWS Market. We additionally dived deep into just a few of the vector database choices with code examples to elucidate the implementation steps.
Check out the code examples on this publish to implement your individual RAG resolution utilizing Amazon Bedrock Information Bases, and share your suggestions and questions within the feedback part.
Concerning the Authors
 Vishwa Gupta is a Senior Information Architect with AWS Skilled Providers. He helps prospects implement generative AI, machine studying, and analytics options. Exterior of labor, he enjoys spending time with household, touring, and making an attempt new meals.
Vishwa Gupta is a Senior Information Architect with AWS Skilled Providers. He helps prospects implement generative AI, machine studying, and analytics options. Exterior of labor, he enjoys spending time with household, touring, and making an attempt new meals.
 Isaac Privitera is a Principal Information Scientist with the AWS Generative AI Innovation Middle, the place he develops bespoke generative AI-based options to handle prospects’ enterprise issues. His main focus lies in constructing accountable AI programs, utilizing methods resembling RAG, multi-agent programs, and mannequin fine-tuning. When not immersed on the planet of AI, Isaac will be discovered on the golf course, having fun with a soccer recreation, or mountaineering trails along with his loyal canine companion, Barry.
Isaac Privitera is a Principal Information Scientist with the AWS Generative AI Innovation Middle, the place he develops bespoke generative AI-based options to handle prospects’ enterprise issues. His main focus lies in constructing accountable AI programs, utilizing methods resembling RAG, multi-agent programs, and mannequin fine-tuning. When not immersed on the planet of AI, Isaac will be discovered on the golf course, having fun with a soccer recreation, or mountaineering trails along with his loyal canine companion, Barry.
 Abhishek Madan is a Senior GenAI Strategist with the AWS Generative AI Innovation Middle. He helps inside groups and prospects in scaling generative AI, machine studying, and analytics options. Exterior of labor, he enjoys taking part in journey sports activities and spending time with household.
Abhishek Madan is a Senior GenAI Strategist with the AWS Generative AI Innovation Middle. He helps inside groups and prospects in scaling generative AI, machine studying, and analytics options. Exterior of labor, he enjoys taking part in journey sports activities and spending time with household.
 Ginni Malik is a Senior Information & ML Engineer with AWS Skilled Providers. She assists prospects by architecting enterprise information lake and ML options to scale their information analytics within the cloud.
Ginni Malik is a Senior Information & ML Engineer with AWS Skilled Providers. She assists prospects by architecting enterprise information lake and ML options to scale their information analytics within the cloud.
 Satish Sarapuri is a Sr. Information Architect, Information Lake at AWS. He helps enterprise-level prospects construct high-performance, extremely out there, cost-effective, resilient, and safe generative AI, information mesh, information lake, and analytics platform options on AWS by way of which prospects could make data-driven choices to realize impactful outcomes for his or her enterprise, and helps them on their digital and information transformation journey. In his spare time, he enjoys spending time along with his household and taking part in tennis.
Satish Sarapuri is a Sr. Information Architect, Information Lake at AWS. He helps enterprise-level prospects construct high-performance, extremely out there, cost-effective, resilient, and safe generative AI, information mesh, information lake, and analytics platform options on AWS by way of which prospects could make data-driven choices to realize impactful outcomes for his or her enterprise, and helps them on their digital and information transformation journey. In his spare time, he enjoys spending time along with his household and taking part in tennis.

{kind=link}