
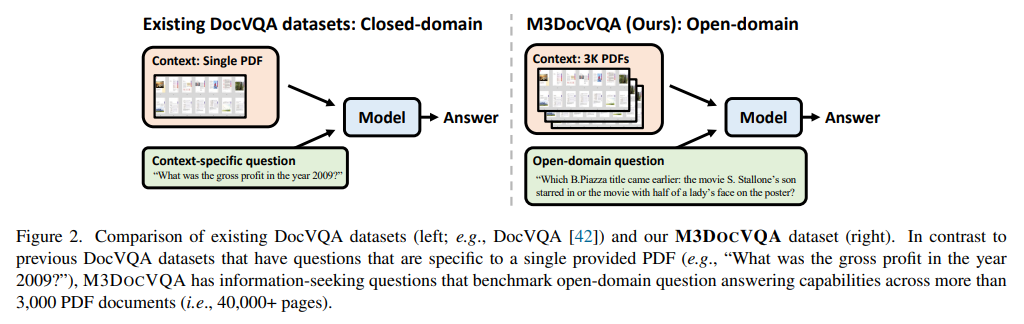
Doc Visible Query Answering (DocVQA) represents a quickly advancing discipline geared toward bettering AI’s means to interpret, analyze, and reply to questions primarily based on advanced paperwork that combine textual content, pictures, tables, and different visible parts. This functionality is more and more beneficial in finance, healthcare, and regulation settings, as it may streamline and help decision-making processes that depend on understanding dense and multifaceted info. Conventional doc processing strategies, nonetheless, typically have to catch up when confronted with these sorts of paperwork, highlighting the necessity for extra refined, multi-modal techniques that may interpret info unfold throughout completely different pages and different codecs.

The first problem in DocVQA is precisely retrieving and deciphering info that spans a number of pages or paperwork. Typical fashions are inclined to give attention to single-page paperwork or depend on easy textual content extraction, which can ignore crucial visible info akin to pictures, charts, and sophisticated layouts. Such limitations hinder AI’s means to completely perceive paperwork in real-world eventualities, the place beneficial info is commonly embedded in various codecs throughout varied pages. These limitations require superior strategies that successfully combine visible and textual information throughout a number of doc pages.
Current DocVQA approaches embrace single-page visible query answering (VQA) and retrieval-augmented era (RAG) techniques that use optical character recognition (OCR) to extract and interpret textual content. Nevertheless, these strategies should nonetheless be absolutely outfitted to deal with the multimodal necessities of detailed doc comprehension. Textual content-based RAG pipelines, whereas purposeful, sometimes fail to retain visible nuances, which might result in incomplete solutions. This hole in efficiency highlights the need of growing a multimodal method able to processing in depth paperwork with out sacrificing accuracy or velocity.
Researchers from UNC Chapel Hill and Bloomberg have launched M3DocRAG, a groundbreaking framework designed to boost AI’s capability to carry out document-level query answering throughout multimodal, multi-page, and multi-document settings. This framework features a multimodal RAG system that successfully incorporates textual content and visible parts, permitting for correct comprehension and question-answering throughout varied doc varieties. M3DocRAG’s design will allow it to work effectively in closed-domain and open-domain eventualities, making it adaptable throughout a number of sectors and functions.
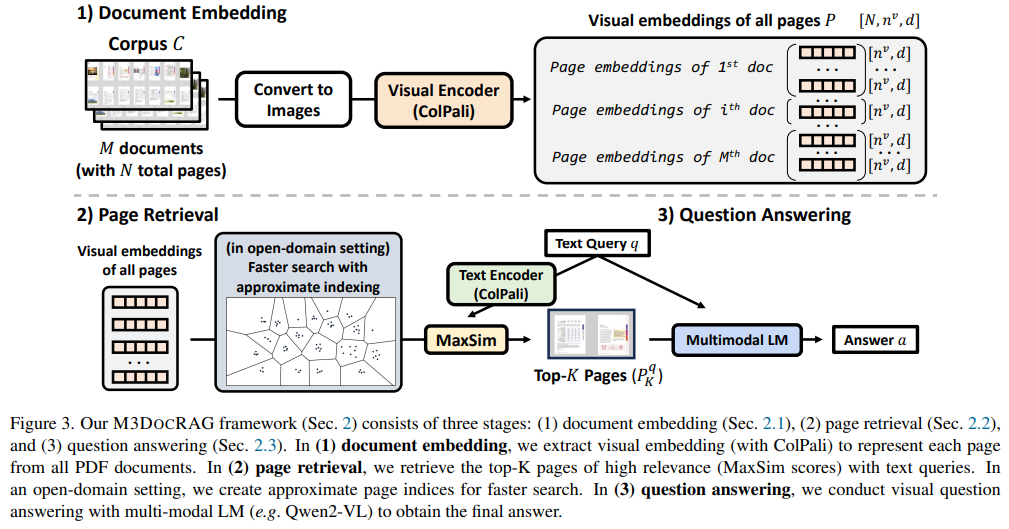
The M3DocRAG framework operates by three main phases. First, it converts all doc pages into pictures and applies visible embeddings to encode web page information, making certain that visible and textual options are retained. Second, it makes use of multi-modal retrieval fashions to establish probably the most related pages from a doc corpus, utilizing superior indexing strategies to optimize search velocity and relevance. Lastly, a multi-modal language mannequin processes these retrieved pages to generate correct solutions to consumer questions. The visible embeddings make sure that important info is preserved throughout a number of pages, addressing the core limitations of prior text-only RAG techniques. M3DocRAG can function on large-scale doc units, dealing with as much as 40,000 pages unfold over 3,368 PDF paperwork with a retrieval latency diminished to below 2 seconds per question, relying on the indexing methodology.
Outcomes from empirical testing present M3DocRAG’s sturdy efficiency throughout three key DocVQA benchmarks: M3D OC VQA, MMLongBench-Doc, and MP-DocVQA. These benchmarks simulate real-world challenges like multi-page reasoning and open-domain query answering. M3DocRAG achieved a 36.5% F1 rating on the open-domain M3D OC VQA benchmark and state-of-the-art efficiency in MP-DocVQA, which requires single-document query answering. The system’s means to precisely retrieve solutions throughout completely different proof modalities (textual content, tables, pictures) underpins its sturdy efficiency. M3DocRAG’s flexibility extends to dealing with advanced eventualities the place solutions rely on multi-page proof or non-textual content material.
Key findings from this analysis spotlight the M3DocRAG system’s benefits over current strategies in a number of essential areas:
- Effectivity: M3DocRAG reduces retrieval latency to below 2 seconds per question for big doc units utilizing optimized indexing, enabling fast response instances.
- Accuracy: The system maintains excessive accuracy throughout different doc codecs and lengths by integrating multi-modal retrieval with language modeling, attaining prime ends in benchmarks like M3D OC VQA and MP-DocVQA.
- Scalability: M3DocRAG successfully manages open-domain query answering for big datasets, dealing with as much as 3,368 paperwork or 40,000+ pages, which units a brand new normal for scalability in DocVQA.
- Versatility: This method accommodates various doc settings in closed-domain (single-document) or open-domain (multi-document) contexts and effectively retrieves solutions throughout completely different proof varieties.

In conclusion, M3DocRAG stands out as an modern resolution within the DocVQA discipline, designed to beat the normal limitations of doc comprehension fashions. It brings a multi-modal, multi-page, and multi-document functionality to AI-based query answering, advancing the sphere by supporting environment friendly and correct retrieval in advanced doc eventualities. By incorporating textual and visible options, M3DocRAG bridges a major hole in doc understanding, providing a scalable and adaptable resolution that may impression quite a few sectors the place complete doc evaluation is crucial. This work encourages future exploration in multi-modal retrieval and era, setting a benchmark for sturdy, scalable, and real-world-ready DocVQA functions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[AI Magazine/Report] Learn Our Newest Report on ‘SMALL LANGUAGE MODELS‘
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}