
{kind=link}
The storage and processing of knowledge is just not a brand new drawback. For the reason that invention of the pc customers have wanted to function on knowledge, reserve it and recollect it at a later date to additional function on it. Over the previous 50 years, an business value tons of of billions of {dollars} (and an thrilling and fulfilling profession for me) has grown to assist this and every part from normal function options on your dwelling consumer (sure Excel counts 😉 ) to very large distributed methods to work on unimaginably massive datasets like these of Google, Fb and LinkedIn can be found.
Occasion streaming is a contemporary tackle this drawback. As an alternative of storing knowledge X, recalling it, reworking it to Y and storing it once more, occasion streaming shops the “occasion” that X was created and the “occasion” that X was modified to Y. Consider it as recording individuals going by way of a turnstile to a soccer recreation moderately than counting the variety of individuals of their seats. This method creates a log of operations that may be learn and responded to by the suitable companies in actual time. The companies that reply to occasions on these logs can sometimes be smaller and extra self-contained than alternate options resulting in extra versatile, resilient and scalable options.
On this article we’re going to have a look at the function and evolution of occasion streaming platforms (software program to retailer, transport and function on occasion streams) and take a look at the place this blossoming sector is headed sooner or later.
The start
Occasion streaming platforms have been designed with a quite simple function in thoughts, to get occasion X from supply A to sink B in a quick and resilient manner. Just like the message queueing methods that preceded them in addition they buffered knowledge in order that if sink B was not but prepared for occasion X it might be saved by the platform till it was.
Trade leaders reminiscent of Apache Kafka (developed at LinkedIn) turned extremely environment friendly at these duties, transporting huge quantities of knowledge at tiny latencies! The success of the occasion streaming platform drove a shift in architectural pondering away from monolithic architectures: massive functions that carry out all of the duties in a enterprise space, in the direction of
microservices: small, impartial companies with a slender scope that talk with one another by way of occasion streams.
On the entire this shift is constructive, breaking down advanced issues into smaller items permits for extra speedy growth, will increase reliability and permits for simpler scaling. A lot has been already written on this topic so I received’t add additional and as a substitute give attention to one facet impact of this shift: that organisations which have transitioned to a microservices structure see much more knowledge transferring between their methods than earlier than. It didn’t take lengthy for somebody to recognise that this “in transit” knowledge might be helpful.
Yesterday: Stream processing
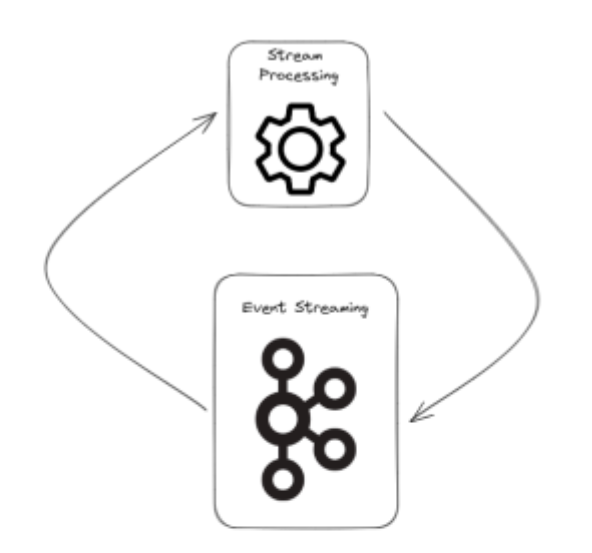
The shift to microservices architectures is pervasive, most organisations shortly see the worth of this shift and shortly make use of it throughout the whole organisation. Stream processing is a pure extension of this the place the supply and sink of a given course of are occasion streams. Utilizing stream processing, occasions from a number of matters (logical streaming items) might be consumed, manipulated and produced out to a different occasion stream prepared for one more service. To stick with our soccer analogy, stream processing would offer a operating depend of individuals within the stadium as they go by way of the turnstile.
One new idea that stream processing launched was state. Occasion values might be collected, saved and referenced within the context of different occasions. As an illustration in our soccer recreation software, we may have one other stream that accommodates updates to season ticket holder particulars (a change of deal with or cellphone quantity). These might be performed right into a retailer that retains the most recent particulars for every buyer. This retailer can then be referenced by processing carried out on different occasion streams, say our turnstile stream, to be sure that any presents for season ticket holders are despatched to the latest deal with.
This sort of work would beforehand have required a database and sophisticated logic to deal with the nuances of occasion streams however stream processing instruments and ideas wrapped this up into a straightforward to handle and develop package deal.
Right this moment: The Streaming Database/Operational Warehouse
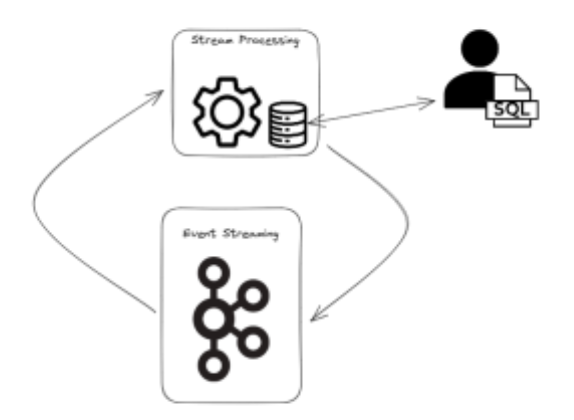
Right this moment we’re beginning to flip the stream processing analogy inside out. The success of stream processing as an structure meant that the method of studying knowledge from an occasion streaming system and “materializing” it to a retailer has turn into commonplace.
It was shortly observed that these shops comprise helpful knowledge appropriate for circumstances past stream processing and a whole new sector was created that supplied this knowledge within the codecs and protocols often related to databases moderately than occasion streaming: Streaming Databases. In a contemporary streaming database customers can write SQL and question views over the streaming knowledge of their occasion streaming platforms. To take the instance above, “SELECT PostCode FROM SeasonTicketHolders WHERE identify = ‘Tom Scott’” would question my retailer of newest addresses and supply me with the proper reply because of this set moderately than as an occasion stream.
Options of this sort are wonderful for offering the well-known benefits of occasion streaming (freshness of knowledge and so on.) but additionally present the benefit of use and prepared entry that comes with SQL.
Tomorrow: The Streaming Datalake
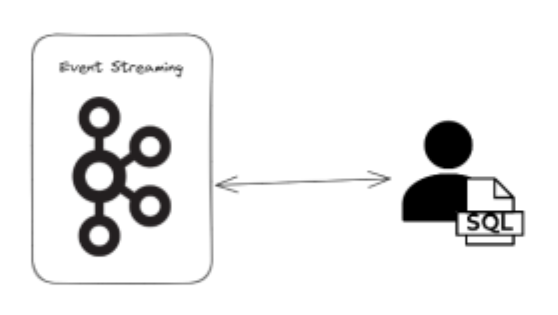
The distinction between a database and a datalake is {that a} database sometimes shops the processed, present knowledge required to energy functions whereas a datalake shops historic and uncooked knowledge usually for the aim of analytics. The occasion streaming model of the database is properly lined by the streaming database choices described above however there is no such thing as a actual model of a datalake throughout the occasion streaming ecosystem at current.
The explanation for that is unlikely to be that there is no such thing as a want. I’ve spoken with many pissed off analysts and knowledge engineers that will love a greater diversity and quantity of knowledge to be made obtainable from occasion streaming platforms (when you ever meet an analyst that doesn’t need extra knowledge please name me 😉 ). As an alternative the issues are largely technical. Occasion streaming platforms weren’t designed for analytical workloads and so storage of enormous quantities of knowledge might be costly and efficiency might be affected once we get to excessive scales when it comes to selection.
Fortunately that is altering, if we take the preferred occasion streaming platform: Apache Kafka, now we have lately seen the introduction of two new options aimed particularly at growing the quantity and number of knowledge saved within the platform:
● KIP-405 – virtually limitless and low-cost storage for knowledge in Kafka
● KIP-833 – a distinct method to metadata that vastly expands the number of knowledge that may be saved in Kafka.
With simply these two modifications (extra are coming) instantly the occasion streaming platform turns into a viable knowledge single supply of fact for all the knowledge in an organisation. Merely change a configuration property and instantly all historic knowledge flowing by way of an occasion streaming platform is retained in a value efficient and simply recallable manner. These architectures are of their infancy however supply vital benefits to the Streaming Platform + ETL/ELT + Datalake architectures which are their equivalents at the moment:
Consistency – Any time there are a number of copies of the identical knowledge consistency should be maintained between them. The standard sample of copying knowledge from an occasion stream into an information warehouse requires further work to make sure that consistency is maintained between the 2. By storing and sourcing the info instantly from the occasion streaming system a single, completely constant, copy of the info is maintained. Analytical workloads might be sure they’re working with the identical knowledge as their operational equivalents.
Complexity – Much less is extra in knowledge infrastructure, the extra transferring items you’ve the extra threat you introduce. A single system to retailer and entry knowledge vastly simplifies an information structure. Streaming Datalakes take away the necessity for advanced ETL/ELT processes and separate Datalake upkeep by transferring knowledge learn on to the supply.
Price – Knowledge storage prices cash and conversely, decreasing the required storage for knowledge infrastructure saves cash. The Streaming datalake removes the necessity for duplicate copies of knowledge within the streaming system and within the separate datalake. A large saving for top knowledge volumes.
A name to arms
The long run is vibrant! By no means earlier than have there been so many choices for knowledge engineers when it comes to the way in which during which knowledge might be saved and offered to customers. Occasion streaming already has a important function in powering the operational issues of contemporary companies however I consider in a future the place the advantages when it comes to knowledge freshness and consistency afforded by occasion streaming might be shared with analytical workloads too. When contemplating new knowledge methods and pipelines involving occasion streaming right here’s 3 rules to assist information your determination making course of:
1. Occasions are higher than details – Info inform the present state however occasions inform the story, when you replace a row in a desk the earlier worth is misplaced and together with it any clues to the explanation it was up to date. The previous tends to be high-quality for operational issues however analytical workloads are all about that historic journey.
2. Knowledge tastes higher from the supply – The purpose at which a chunk of knowledge is generated is the purpose at which it’s most right, recent and purposeful. It wouldn’t be generated if this was not the case. This precept might be carried on to knowledge customers: the nearer they’re to the supply the extra versatile and full their utilization of the info might be.
3. Resiliency effectivity is greater than the sum of its elements – All trendy methods are resilient however virtually all the resiliency options of 1 system can’t be utilized by one other. Streamlining your structure can keep the identical resilience with out counting on expensive and sophisticated resilience options in a number of methods.
Occasion streaming is right here to remain and, with efficient utilization, the info journey from uncooked to related has by no means been shorter. Seize the alternatives supplied by this recreation altering expertise and the actual time future it presents.
In regards to the Creator

Very long time fanatic of Kafka and all issues knowledge integration, Tom Scott has greater than 10 years expertise (5yrs+ Kafka) in modern and environment friendly methods to retailer, question and transfer knowledge. Tom is pioneering the Streaming Datalake at Streambased. An thrilling new method to uncooked and historic knowledge administration in your occasion streaming infrastructure.
Join the free insideBIGDATA e-newsletter.
Be part of us on Twitter: https://twitter.com/InsideBigData1
Be part of us on LinkedIn: https://www.linkedin.com/firm/insidebigdata/
Be part of us on Fb: https://www.fb.com/insideBIGDATANOW