
{kind=link}
It is a visitor publish written by Axfood AB.
On this publish, we share how Axfood, a big Swedish meals retailer, improved operations and scalability of their current synthetic intelligence (AI) and machine studying (ML) operations by prototyping in shut collaboration with AWS specialists and utilizing Amazon SageMaker.
Axfood is Sweden’s second largest meals retailer, with over 13,000 staff and greater than 300 shops. Axfood has a construction with a number of decentralized information science groups with totally different areas of duty. Along with a central information platform staff, the information science groups carry innovation and digital transformation by AI and ML options to the group. Axfood has been utilizing Amazon SageMaker to domesticate their information utilizing ML and has had fashions in manufacturing for a few years. Recently, the extent of sophistication and the sheer variety of fashions in manufacturing is growing exponentially. Nevertheless, though the tempo of innovation is excessive, the totally different groups had developed their very own methods of working and have been seeking a brand new MLOps greatest apply.
Our problem
To remain aggressive when it comes to cloud providers and AI/ML, Axfood selected to associate with AWS and has been collaborating with them for a few years.
Throughout certainly one of our recurring brainstorming periods with AWS, we have been discussing greatest collaborate throughout groups to extend the tempo of innovation and effectivity of information science and ML practitioners. We determined to place in a joint effort to construct a prototype on a greatest apply for MLOps. The goal of the prototype was to construct a mannequin template for all information science groups to construct scalable and environment friendly ML fashions—the inspiration to a brand new era of AI and ML platforms for Axfood. The template ought to bridge and mix greatest practices from AWS ML specialists and company-specific greatest apply fashions—one of the best of each worlds.
We determined to construct a prototype from one of many at present most developed ML fashions inside Axfood: forecasting gross sales in shops. Extra particularly, the forecast for vegatables and fruits of upcoming campaigns for meals retail shops. Correct each day forecasting helps the ordering course of for the shops, growing sustainability by minimizing meals waste because of optimizing gross sales by precisely predicting the wanted in-store inventory ranges. This was the proper place to begin for our prototype—not solely would Axfood achieve a brand new AI/ML platform, however we’d additionally get an opportunity to benchmark our ML capabilities and be taught from main AWS specialists.
Our answer: A brand new ML template on Amazon SageMaker Studio
Constructing a full ML pipeline that’s designed for an precise enterprise case might be difficult. On this case, we’re growing a forecasting mannequin, so there are two foremost steps to finish:
- Practice the mannequin to make predictions utilizing historic information.
- Apply the educated mannequin to make predictions of future occasions.
In Axfood’s case, a well-functioning pipeline for this function was already arrange utilizing SageMaker notebooks and orchestrated by the third-party workflow administration platform Airflow. Nevertheless, there are various clear advantages of modernizing our ML platform and shifting to Amazon SageMaker Studio and Amazon SageMaker Pipelines. Transferring to SageMaker Studio gives many predefined out-of-the-box options:
- Monitoring mannequin and information high quality in addition to mannequin explainability
- Constructed-in built-in growth atmosphere (IDE) instruments resembling debugging
- Value/efficiency monitoring
- Mannequin acceptance framework
- Mannequin registry
Nevertheless, a very powerful incentive for Axfood is the flexibility to create customized challenge templates utilizing Amazon SageMaker Initiatives for use as a blueprint for all information science groups and ML practitioners. The Axfood staff already had a sturdy and mature stage of ML modeling, so the primary focus was on constructing the brand new structure.
Answer overview
Axfood’s proposed new ML framework is structured round two foremost pipelines: the mannequin construct pipeline and the batch inference pipeline:
- These pipelines are versioned inside two separate Git repositories: one construct repository and one deploy (inference) repository. Collectively, they kind a sturdy pipeline for forecasting vegatables and fruits.
- The pipelines are packaged right into a customized challenge template utilizing SageMaker Initiatives in integration with a third-party Git repository (Bitbucket) and Bitbucket pipelines for steady integration and steady deployment (CI/CD) elements.
- The SageMaker challenge template contains seed code corresponding to every step of the construct and deploy pipelines (we talk about these steps in additional element later on this publish) in addition to the pipeline definition—the recipe for a way the steps ought to be run.
- Automation of constructing new initiatives primarily based on the template is streamlined by AWS Service Catalog, the place a portfolio is created, serving as an abstraction for a number of merchandise.
- Every product interprets into an AWS CloudFormation template, which is deployed when a knowledge scientist creates a brand new SageMaker challenge with our MLOps blueprint as the inspiration. This prompts an AWS Lambda perform that creates a Bitbucket challenge with two repositories—mannequin construct and mannequin deploy—containing the seed code.
The next diagram illustrates the answer structure. Workflow A depicts the intricate movement between the 2 mannequin pipelines—construct and inference. Workflow B reveals the movement to create a brand new ML challenge.
Mannequin construct pipeline
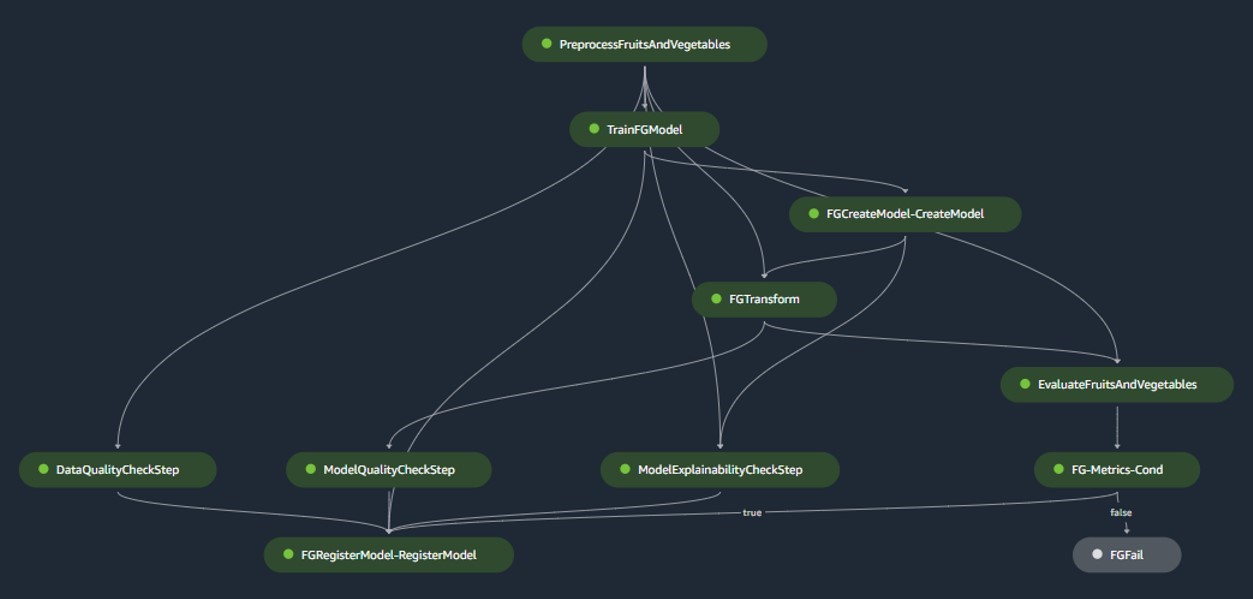
The mannequin construct pipeline orchestrates the mannequin’s lifecycle, starting from preprocessing, shifting by coaching, and culminating in being registered within the mannequin registry:
- Preprocessing – Right here, the SageMaker
ScriptProcessorclass is employed for characteristic engineering, ensuing within the dataset the mannequin will likely be educated on. - Coaching and batch rework – Customized coaching and inference containers from SageMaker are harnessed to coach the mannequin on historic information and create predictions on the analysis information utilizing a SageMaker Estimator and Transformer for the respective duties.
- Analysis – The educated mannequin undergoes analysis by evaluating the generated predictions on the analysis information to the bottom reality utilizing
ScriptProcessor. - Baseline jobs – The pipeline creates baselines primarily based on statistics within the enter information. These are important for monitoring information and mannequin high quality, in addition to characteristic attributions.
- Mannequin registry – The educated mannequin is registered for future use. The mannequin will likely be authorised by designated information scientists to deploy the mannequin to be used in manufacturing.
For manufacturing environments, information ingestion and set off mechanisms are managed through a main Airflow orchestration. In the meantime, throughout growth, the pipeline is activated every time a brand new commit is launched to the mannequin construct Bitbucket repository. The next determine visualizes the mannequin construct pipeline.
Batch inference pipeline
The batch inference pipeline handles the inference section, which consists of the next steps:
- Preprocessing – Knowledge is preprocessed utilizing
ScriptProcessor. - Batch rework – The mannequin makes use of the customized inference container with a SageMaker Transformer and generates predictions given the enter preprocessed information. The mannequin used is the most recent authorised educated mannequin within the mannequin registry.
- Postprocessing – The predictions bear a collection of postprocessing steps utilizing
ScriptProcessor. - Monitoring – Steady surveillance completes checks for drifts associated to information high quality, mannequin high quality, and have attribution.
If discrepancies come up, a enterprise logic inside the postprocessing script assesses whether or not retraining the mannequin is critical. The pipeline is scheduled to run at common intervals.
The next diagram illustrates the batch inference pipeline. Workflow A corresponds to preprocessing, information high quality and have attribution drift checks, inference, and postprocessing. Workflow B corresponds to mannequin high quality drift checks. These pipelines are divided as a result of the mannequin high quality drift examine will solely run if new floor reality information is on the market.

SageMaker Mannequin Monitor
With Amazon SageMaker Mannequin Monitor built-in, the pipelines profit from real-time monitoring on the next:
- Knowledge high quality – Screens any drift or inconsistencies in information
- Mannequin high quality – Watches for any fluctuations in mannequin efficiency
- Characteristic attribution – Checks for drift in characteristic attributions
Monitoring mannequin high quality requires entry to floor reality information. Though acquiring floor reality might be difficult at occasions, utilizing information or characteristic attribution drift monitoring serves as a reliable proxy to mannequin high quality.
Particularly, within the case of information high quality drift, the system watches out for the next:
- Idea drift – This pertains to modifications within the correlation between enter and output, requiring floor reality
- Covariate shift – Right here, the emphasis is on alterations within the distribution of unbiased enter variables
SageMaker Mannequin Monitor’s information drift performance meticulously captures and scrutinizes the enter information, deploying guidelines and statistical checks. Alerts are raised each time anomalies are detected.
In parallel to utilizing information high quality drift checks as a proxy for monitoring mannequin degradation, the system additionally displays characteristic attribution drift utilizing the normalized discounted cumulative achieve (NDCG) rating. This rating is delicate to each modifications in characteristic attribution rating order in addition to to the uncooked attribution scores of options. By monitoring drift in attribution for particular person options and their relative significance, it’s simple to identify degradation in mannequin high quality.
Mannequin explainability
Mannequin explainability is a pivotal a part of ML deployments, as a result of it ensures transparency in predictions. For an in depth understanding, we use Amazon SageMaker Make clear.
It presents each world and native mannequin explanations by a model-agnostic characteristic attribution method primarily based on the Shapley worth idea. That is used to decode why a selected prediction was made throughout inference. Such explanations, that are inherently contrastive, can range primarily based on totally different baselines. SageMaker Make clear aids in figuring out this baseline utilizing Okay-means or Okay-prototypes within the enter dataset, which is then added to the mannequin construct pipeline. This performance permits us to construct generative AI functions sooner or later for elevated understanding of how the mannequin works.
Industrialization: From prototype to manufacturing
The MLOps challenge features a excessive diploma of automation and may function a blueprint for comparable use circumstances:
- The infrastructure might be reused fully, whereas the seed code might be tailored for every job, with most modifications restricted to the pipeline definition and the enterprise logic for preprocessing, coaching, inference, and postprocessing.
- The coaching and inference scripts are hosted utilizing SageMaker customized containers, so a wide range of fashions might be accommodated with out modifications to the information and mannequin monitoring or mannequin explainability steps, so long as the information is in tabular format.
After ending the work on the prototype, we turned to how we must always use it in manufacturing. To take action, we felt the necessity to make some extra changes to the MLOps template:
- The unique seed code used within the prototype for the template included preprocessing and postprocessing steps run earlier than and after the core ML steps (coaching and inference). Nevertheless, when scaling up to make use of the template for a number of use circumstances in manufacturing, the built-in preprocessing and postprocessing steps might result in decreased generality and replica of code.
- To enhance generality and reduce repetitive code, we selected to slim down the pipelines even additional. As a substitute of operating the preprocessing and postprocessing steps as a part of the ML pipeline, we run these as a part of the first Airflow orchestration earlier than and after triggering the ML pipeline.
- This fashion, use case-specific processing duties are abstracted from the template, and what’s left is a core ML pipeline performing duties which might be basic throughout a number of use circumstances with minimal repetition of code. Parameters that differ between use circumstances are provided as enter to the ML pipeline from the first Airflow orchestration.
The consequence: A fast & environment friendly strategy to mannequin construct & deployment
The prototype in collaboration with AWS has resulted in an MLOps template following present greatest practices that’s now out there to be used to all of Axfood’s information science groups. By creating a brand new SageMaker challenge inside SageMaker Studio, information scientists can get began on new ML initiatives rapidly and seamlessly transition to manufacturing, permitting for extra environment friendly time administration. That is made attainable by automating tedious, repetitive MLOps duties as a part of the template.
Moreover, a number of new functionalities have been added in an automatic trend to our ML setup. These beneficial properties embody:
- Mannequin monitoring – We will carry out drift checks for mannequin and information high quality in addition to mannequin explainability
- Mannequin and information lineage – It’s now attainable to hint precisely which information has been used for which mannequin
- Mannequin registry – This helps us catalog fashions for manufacturing and handle mannequin variations
Conclusion
On this publish, we mentioned how Axfood improved operations and scalability of our current AI and ML operations in collaboration with AWS specialists and by utilizing SageMaker and its associated merchandise.
These enhancements will assist Axfood’s information science groups constructing ML workflows in a extra standardized means and can tremendously simplify evaluation and monitoring of fashions in manufacturing—guaranteeing the standard of ML fashions constructed and maintained by our groups.
Please go away any suggestions or questions within the feedback part.
Concerning the Authors
 Dr. Björn Blomqvist is the Head of AI Technique at Axfood AB. Earlier than becoming a member of Axfood AB he led a staff of Knowledge Scientists at Dagab, part of Axfood, constructing revolutionary machine studying options with the mission to supply good and sustainable meals to individuals throughout Sweden. Born and raised within the north of Sweden, in his spare time Björn ventures to snowy mountains and open seas.
Dr. Björn Blomqvist is the Head of AI Technique at Axfood AB. Earlier than becoming a member of Axfood AB he led a staff of Knowledge Scientists at Dagab, part of Axfood, constructing revolutionary machine studying options with the mission to supply good and sustainable meals to individuals throughout Sweden. Born and raised within the north of Sweden, in his spare time Björn ventures to snowy mountains and open seas.
 Oskar Klang is a Senior Knowledge Scientist on the analytics division at Dagab, the place he enjoys working with every part analytics and machine studying, e.g. optimizing provide chain operations, constructing forecasting fashions and, extra just lately, GenAI functions. He’s dedicated to constructing extra streamlined machine studying pipelines, enhancing effectivity and scalability.
Oskar Klang is a Senior Knowledge Scientist on the analytics division at Dagab, the place he enjoys working with every part analytics and machine studying, e.g. optimizing provide chain operations, constructing forecasting fashions and, extra just lately, GenAI functions. He’s dedicated to constructing extra streamlined machine studying pipelines, enhancing effectivity and scalability.
 Pavel Maslov is a Senior DevOps and ML engineer within the Analytic Platforms staff. Pavel has intensive expertise within the growth of frameworks, infrastructure, and instruments within the domains of DevOps and ML/AI on the AWS platform. Pavel has been one of many key gamers in constructing the foundational functionality inside ML at Axfood.
Pavel Maslov is a Senior DevOps and ML engineer within the Analytic Platforms staff. Pavel has intensive expertise within the growth of frameworks, infrastructure, and instruments within the domains of DevOps and ML/AI on the AWS platform. Pavel has been one of many key gamers in constructing the foundational functionality inside ML at Axfood.
 Joakim Berg is the Crew Lead and Product Proprietor Analytic Platforms, primarily based in Stockholm Sweden. He’s main a staff of Knowledge Platform finish DevOps/MLOps engineers offering Knowledge and ML platforms for the Knowledge Science groups. Joakim has a few years of expertise main senior growth and structure groups from totally different industries.
Joakim Berg is the Crew Lead and Product Proprietor Analytic Platforms, primarily based in Stockholm Sweden. He’s main a staff of Knowledge Platform finish DevOps/MLOps engineers offering Knowledge and ML platforms for the Knowledge Science groups. Joakim has a few years of expertise main senior growth and structure groups from totally different industries.