
Recognition of human movement utilizing time sequence from cell and wearable gadgets is often used as key context info for numerous functions, from well being situation monitoring to sports activities exercise evaluation to consumer behavior research. Nonetheless, gathering large-scale movement time sequence knowledge stays difficult because of safety or privateness considerations. Within the movement time sequence area, the shortage of datasets and an efficient pre-training job makes it troublesome to develop related fashions that may function with restricted knowledge. Sometimes, present fashions carry out coaching and testing on the identical dataset, and so they wrestle to generalize throughout completely different datasets given three distinctive challenges throughout the movement time sequence downside area: First, inserting gadgets in several places on the physique—like on the wrist versus the leg—results in very completely different knowledge, which makes it robust to make use of a mannequin skilled for one spot on one other half. Second, since gadgets may be held in numerous orientations, it’s problematic as a result of fashions skilled with a tool in a single place usually wrestle when the system is held in another way. Lastly, completely different datasets usually concentrate on several types of actions, making it laborious to check or mix the information successfully.



The standard movement time sequence classification depends on separate classifiers for every dataset, utilizing strategies like statistical function extraction, CNNs, RNNs, and a focus fashions. Basic-purpose fashions like TimesNet and SHARE goal for job versatility, however they require coaching or testing on the identical dataset; therefore, they restrict adaptability. Self-supervised studying helps in illustration studying, although generalization throughout numerous datasets stays difficult. Pretrained fashions like ImageBind and IMU2CLIP take into account movement and textual content knowledge, however they’re constrained by device-specific coaching. Strategies that use giant language fashions (LLMs) depend on prompts however have problem recognizing advanced actions as they aren’t skilled on uncooked movement time sequence and wrestle with precisely recognizing advanced actions.
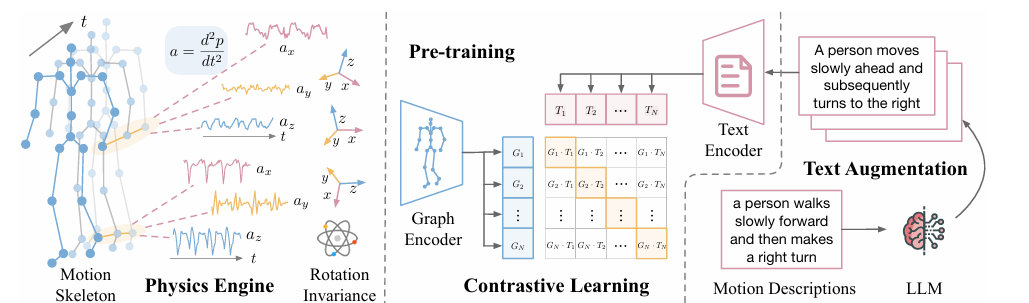
A bunch of researchers from UC San Diego, Amazon, and Qualcomm proposed UniMTS as the primary unified pre-training process for movement time sequence that generalizes throughout various system latent components and actions. UniMTS makes use of a contrastive studying framework to hyperlink movement time sequence knowledge with enriched textual content descriptions from giant language fashions (LLMs). This helps the mannequin to grasp the which means behind completely different actions and permits it to generalize throughout numerous actions. For big-scale pre-training, UniMTS generates movement time sequence knowledge based mostly on present detailed skeleton knowledge, which covers numerous physique elements. The generated knowledge is then processed utilizing graph networks to seize each spatial and temporal relationships throughout completely different system places, serving to the mannequin generalize to knowledge from completely different system placements.
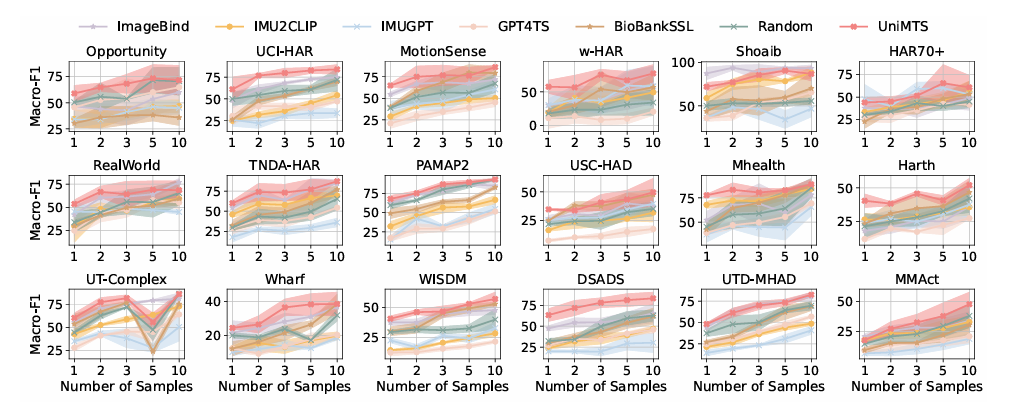
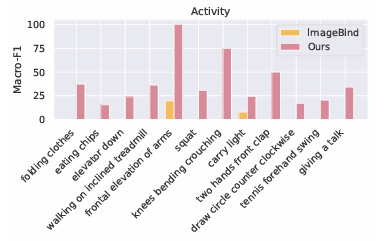
The method begins by creating movement knowledge from skeleton actions and adjusting it in response to completely different orientations. It additionally makes use of a graph encoder to grasp how joints join so it may well work properly throughout completely different gadgets. The textual content descriptions are improved utilizing giant language fashions. To create movement knowledge, it calculates the velocities and accelerations of every joint whereas it considers their positions and orientations, including noise to imitate real-world sensor errors. To deal with inconsistencies in system orientation, UniMTS makes use of knowledge augmentation to create random orientations throughout pre-training. This methodology takes under consideration variations in system positions and axis setups. By aligning movement knowledge with textual content descriptions, the mannequin can adapt properly to completely different orientations and exercise sorts. For coaching, UniMTS employs rotation-invariant knowledge augmentation to deal with system positioning variations. It was examined on the HumanML3D dataset and 18 different real-world movement time sequence benchmark datasets, notably with a efficiency enchancment of 340% within the zero-shot setting, 16.3% within the few-shot setting, and 9.2% within the full-shot setting, in contrast with the respective best-performing baselines. The mannequin’s efficiency was in comparison with baselines like ImageBind and IMU2CLIP. Outcomes confirmed UniMTS outperformed different fashions, notably in zero-shot settings, based mostly on statistical checks that confirmed important enhancements.
In conclusion, the proposed pre-trained mannequin UniMTS is solely based mostly on physics-simulated knowledge, but it exhibits outstanding generalization throughout various real-world movement time sequence datasets that includes completely different system places, orientations, and actions. Whereas leveraging its efficiency from conventional strategies, UniMTS possesses some limitations, too. In a broader sense, this pre-trained movement time sequence classification mannequin can act as a possible base for the upcoming analysis within the discipline of human movement recognition!
Try the Paper, GitHub, and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and resolve challenges.
![IGP [CPS] WW](data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIzMDAiIGhlaWdodD0iMjUwIiB2aWV3Qm94PSIwIDAgMzAwIDI1MCI+PHJlY3Qgd2lkdGg9IjEwMCUiIGhlaWdodD0iMTAwJSIgc3R5bGU9ImZpbGw6I2NmZDRkYjtmaWxsLW9wYWNpdHk6IDAuMTsiLz48L3N2Zz4=)

{kind=link}