

Picture by Writer
Accessing ChatGPT on-line may be very easy – all you want is an web connection and a very good browser. Nevertheless, by doing so, it’s possible you’ll be compromising your privateness and information. OpenAI shops your immediate responses and different metadata to retrain the fashions. Whereas this may not be a priority for some, others who’re privacy-conscious might favor to make use of these fashions regionally with none exterior monitoring.
On this publish, we’ll talk about 5 methods to make use of massive language fashions (LLMs) regionally. Many of the software program is appropriate with all main working techniques and could be simply downloaded and put in for rapid use. Through the use of LLMs in your laptop computer, you’ve got the liberty to decide on your individual mannequin. You simply have to obtain the mannequin from the HuggingFace hub and begin utilizing it. Moreover, you’ll be able to grant these purposes entry to your mission folder and generate context-aware responses.
GPT4All is a cutting-edge open-source software program that permits customers to obtain and set up state-of-the-art open-source fashions with ease.
Merely obtain GPT4ALL from the web site and set up it in your system. Subsequent, select the mannequin from the panel that fits your wants and begin utilizing it. When you have CUDA (Nvidia GPU) put in, GPT4ALL will routinely begin utilizing your GPU to generate fast responses of as much as 30 tokens per second.
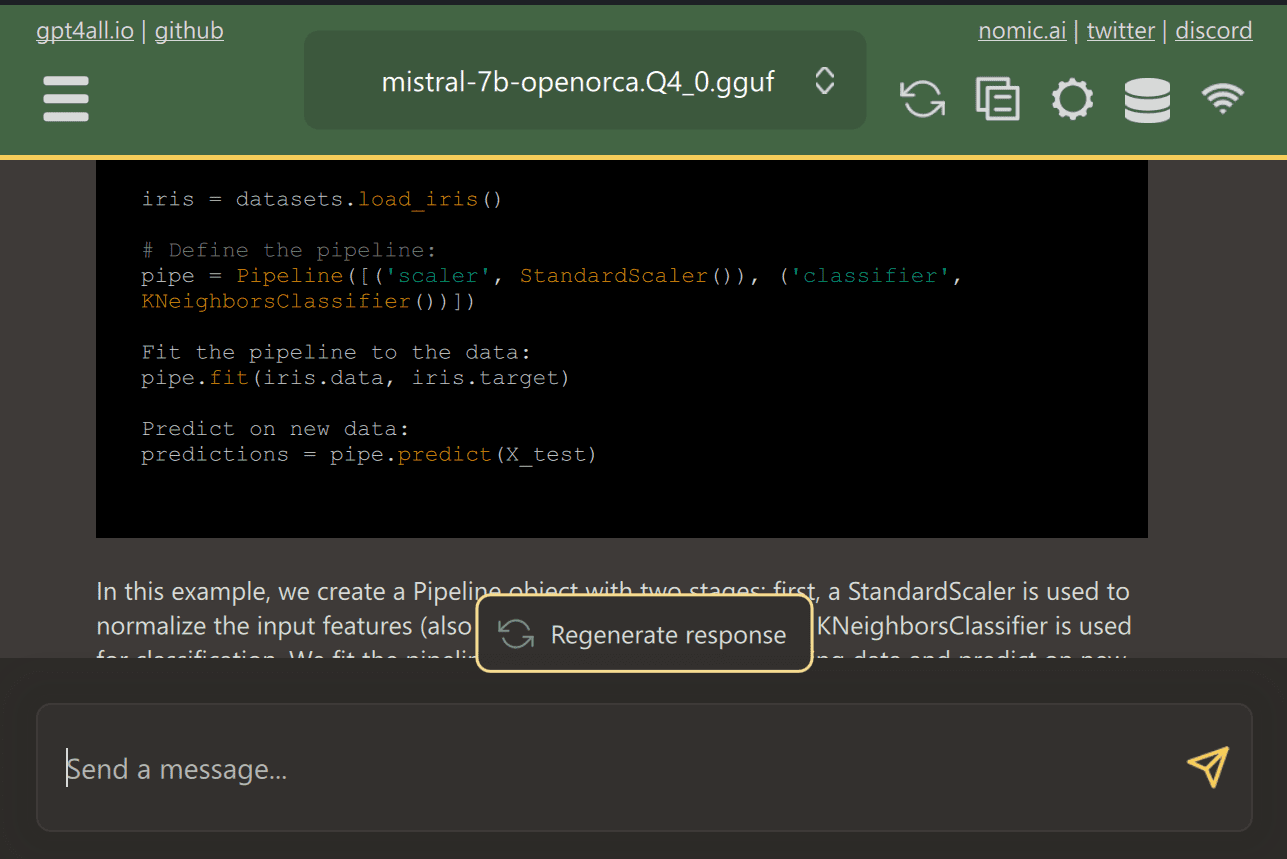
You may present entry to a number of folders containing necessary paperwork and code, and GPT4ALL will generate responses utilizing Retrieval-Augmented Technology. GPT4ALL is user-friendly, quick, and fashionable among the many AI group.
Learn the weblog about GPT4ALL to be taught extra about options and use instances: The Final Open-Supply Giant Language Mannequin Ecosystem.
LM Studio is a brand new software program that gives a number of benefits over GPT4ALL. The consumer interface is superb, and you may set up any mannequin from Hugging Face Hub with a couple of clicks. Moreover, it supplies GPU offloading and different choices that aren’t obtainable in GPT4ALL. Nevertheless, LM Studio is a closed supply, and it does not have the choice to generate context-aware responses by studying mission information.
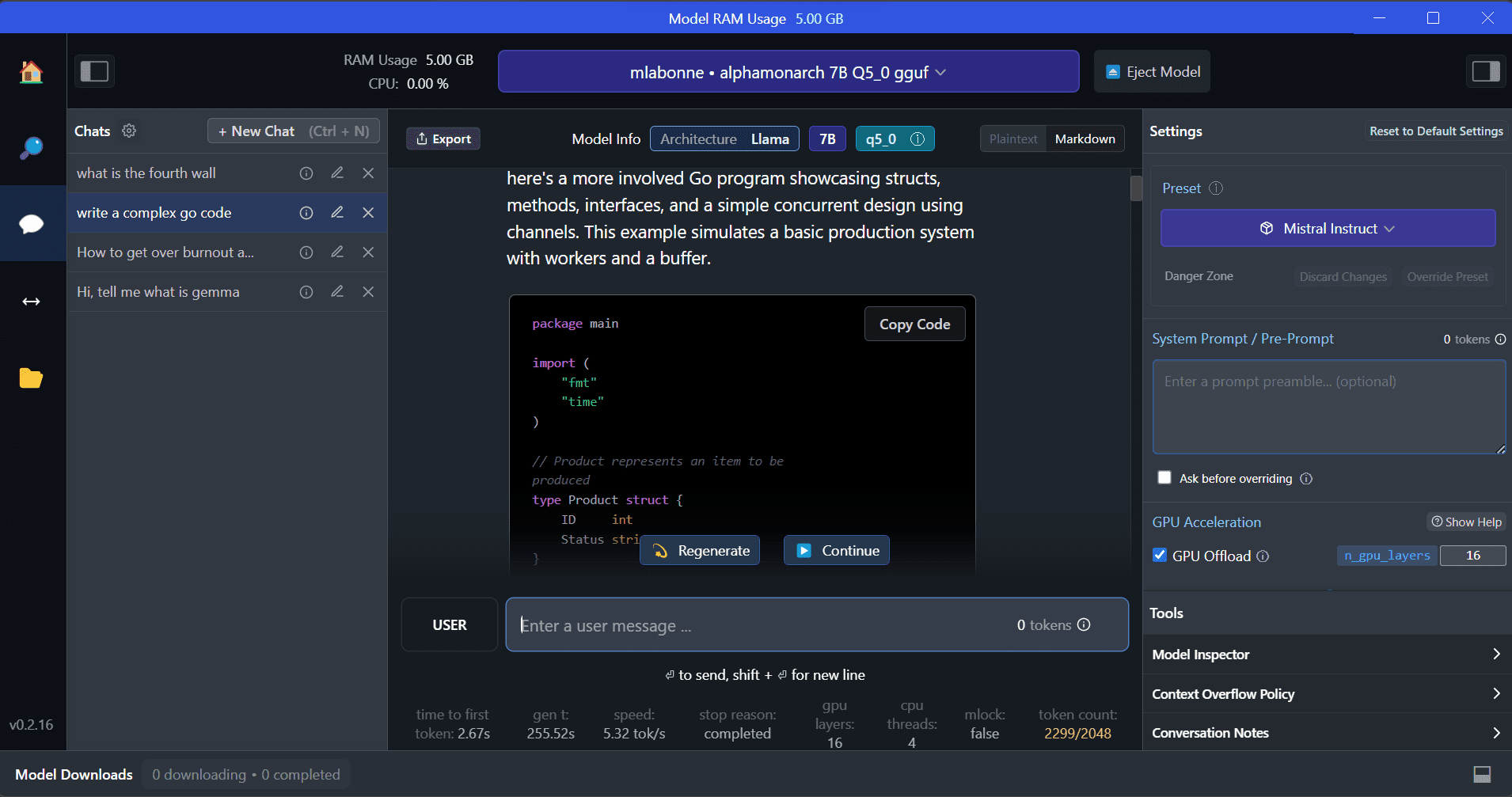
LM Studio presents entry to 1000’s of open-source LLMs, permitting you to start out a neighborhood inference server that behaves like OpenAI’s API. You may modify your LLM’s response by means of the interactive consumer interface with a number of choices.
Additionally, learn Run an LLM Regionally with LM Studio to be taught extra about LM Studio and its key options.
Ollama is a command-line interface (CLI) instrument that permits speedy operation for giant language fashions equivalent to Llama 2, Mistral, and Gemma. If you’re a hacker or developer, this CLI instrument is a improbable choice. You may obtain and set up the software program and use `the llama run llama2` command to start out utilizing the LLaMA 2 mannequin. You’ll find different mannequin instructions within the GitHub repository.

It additionally lets you begin a neighborhood HTTP server that may be built-in with different purposes. For example, you should utilize the Code GPT VSCode extension by offering the native server deal with and begin utilizing it as an AI coding assistant.
Enhance your coding and information workflow with these High 5 AI Coding Assistants.
LLaMA.cpp is a instrument that gives each a CLI and a Graphical Person Interface (GUI). It lets you use any open-source LLMs regionally with none problem. This instrument is extremely customizable and supplies quick responses to any question, as it’s fully written in pure C/C++.
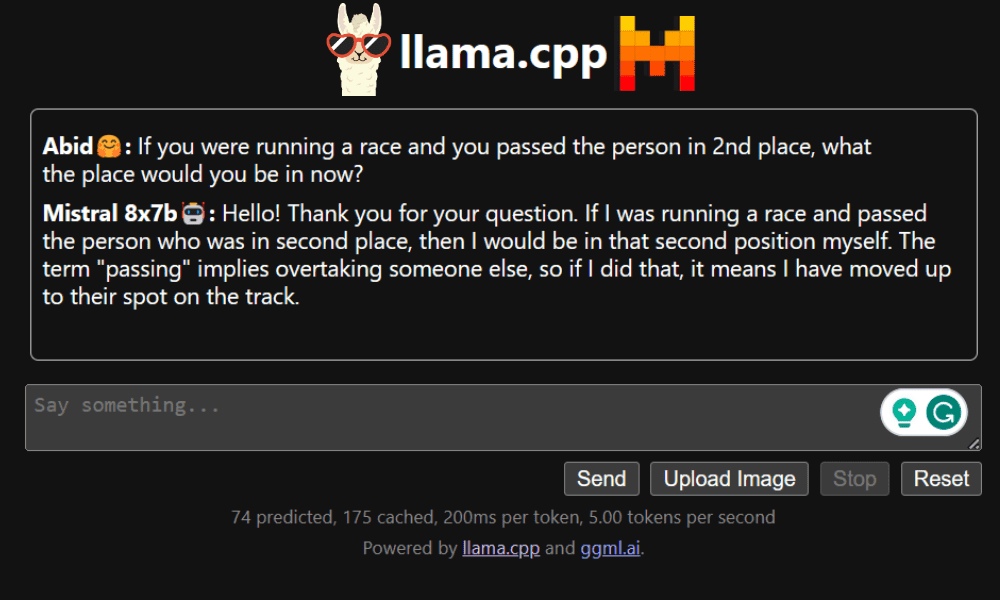
LLaMA.cpp helps all varieties of working techniques, CPUs, and GPUs. You can too use multimodal fashions equivalent to LLaVA, BakLLaVA, Obsidian, and ShareGPT4V.
Learn to Run Mixtral 8x7b On Google Colab For Free utilizing LLaMA.cpp and Google GPUs.
To make use of NVIDIA Chat with RTX, you should obtain and set up the Home windows 11 utility in your laptop computer. This utility is appropriate with laptops which have a 30 sequence or 40 sequence RTX NVIDIA graphics card with at the very least 8GB of RAM and 50GB of free space for storing. Moreover, your laptop computer ought to have at the very least 16GB of RAM to run Chat with RTX easily.
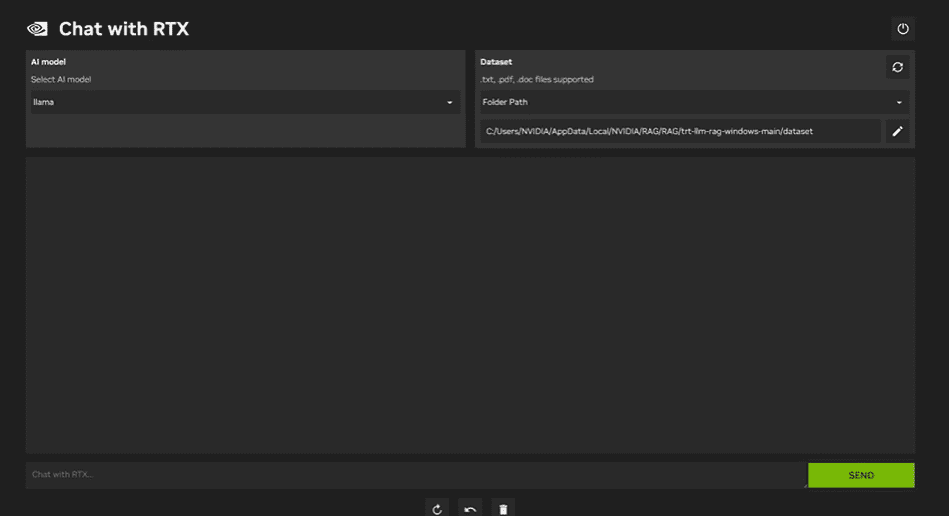
With Chat with RTX, you’ll be able to run LLaMA and Mistral fashions regionally in your laptop computer. It is a quick and environment friendly utility that may even be taught from paperwork you present or YouTube movies. Nevertheless, it is necessary to notice that Chat with RTX depends on TensorRTX-LLM, which is simply supported on 30 sequence GPUs or newer.
If you wish to reap the benefits of the newest LLMs whereas retaining your information secure and personal, you should utilize instruments like GPT4All, LM Studio, Ollama, LLaMA.cpp, or NVIDIA Chat with RTX. Every instrument has its personal distinctive strengths, whether or not it is an easy-to-use interface, command-line accessibility, or help for multimodal fashions. With the correct setup, you’ll be able to have a robust AI assistant that generates custom-made context-aware responses.
I recommend beginning with GPT4All and LM Studio as they cowl a lot of the fundamental wants. After that, you’ll be able to strive Ollama and LLaMA.cpp, and eventually, strive Chat with RTX.
Abid Ali Awan (@1abidaliawan) is a licensed information scientist skilled who loves constructing machine studying fashions. At present, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in Know-how Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students combating psychological sickness.

{kind=link}