
This weblog is co-written with Josh Reini, Shayak Sen and Anupam Datta from TruEra
Amazon SageMaker JumpStart offers quite a lot of pretrained basis fashions reminiscent of Llama-2 and Mistal 7B that may be shortly deployed to an endpoint. These basis fashions carry out properly with generative duties, from crafting textual content and summaries, answering questions, to producing photographs and movies. Regardless of the nice generalization capabilities of those fashions, there are sometimes use instances the place these fashions must be tailored to new duties or domains. One approach to floor this want is by evaluating the mannequin in opposition to a curated floor reality dataset. After the necessity to adapt the inspiration mannequin is obvious, you should use a set of strategies to hold that out. A preferred strategy is to fine-tune the mannequin utilizing a dataset that’s tailor-made to the use case. Wonderful-tuning can enhance the inspiration mannequin and its efficacy can once more be measured in opposition to the bottom reality dataset. This pocket book exhibits the best way to fine-tune fashions with SageMaker JumpStart.
One problem with this strategy is that curated floor reality datasets are costly to create. On this submit, we deal with this problem by augmenting this workflow with a framework for extensible, automated evaluations. We begin off with a baseline basis mannequin from SageMaker JumpStart and consider it with TruLens, an open supply library for evaluating and monitoring giant language mannequin (LLM) apps. After we determine the necessity for adaptation, we are able to use fine-tuning in SageMaker JumpStart and ensure enchancment with TruLens.
TruLens evaluations use an abstraction of suggestions capabilities. These capabilities will be applied in a number of methods, together with BERT-style fashions, appropriately prompted LLMs, and extra. TruLens’ integration with Amazon Bedrock lets you run evaluations utilizing LLMs out there from Amazon Bedrock. The reliability of the Amazon Bedrock infrastructure is especially beneficial to be used in performing evaluations throughout improvement and manufacturing.
This submit serves as each an introduction to TruEra’s place within the trendy LLM app stack and a hands-on information to utilizing Amazon SageMaker and TruEra to deploy, fine-tune, and iterate on LLM apps. Right here is the whole pocket book with code samples to indicate efficiency analysis utilizing TruLens
TruEra within the LLM app stack
TruEra lives on the observability layer of LLM apps. Though new parts have labored their manner into the compute layer (fine-tuning, immediate engineering, mannequin APIs) and storage layer (vector databases), the necessity for observability stays. This want spans from improvement to manufacturing and requires interconnected capabilities for testing, debugging, and manufacturing monitoring, as illustrated within the following determine.
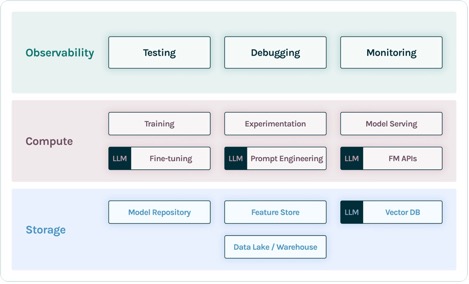
In improvement, you should use open supply TruLens to shortly consider, debug, and iterate in your LLM apps in your setting. A complete suite of analysis metrics, together with each LLM-based and conventional metrics out there in TruLens, lets you measure your app in opposition to standards required for transferring your utility to manufacturing.
In manufacturing, these logs and analysis metrics will be processed at scale with TruEra manufacturing monitoring. By connecting manufacturing monitoring with testing and debugging, dips in efficiency reminiscent of hallucination, security, safety, and extra will be recognized and corrected.
Deploy basis fashions in SageMaker
You may deploy basis fashions reminiscent of Llama-2 in SageMaker with simply two traces of Python code:
Invoke the mannequin endpoint
After deployment, you’ll be able to invoke the deployed mannequin endpoint by first making a payload containing your inputs and mannequin parameters:
Then you’ll be able to merely cross this payload to the endpoint’s predict methodology. Be aware that it’s essential to cross the attribute to simply accept the end-user license settlement every time you invoke the mannequin:
Consider efficiency with TruLens
Now you should use TruLens to arrange your analysis. TruLens is an observability software, providing an extensible set of suggestions capabilities to trace and consider LLM-powered apps. Suggestions capabilities are important right here in verifying the absence of hallucination within the app. These suggestions capabilities are applied through the use of off-the-shelf fashions from suppliers reminiscent of Amazon Bedrock. Amazon Bedrock fashions are a bonus right here due to their verified high quality and reliability. You may arrange the supplier with TruLens by way of the next code:
On this instance, we use three suggestions capabilities: reply relevance, context relevance, and groundedness. These evaluations have shortly change into the usual for hallucination detection in context-enabled query answering functions and are particularly helpful for unsupervised functions, which cowl the overwhelming majority of as we speak’s LLM functions.
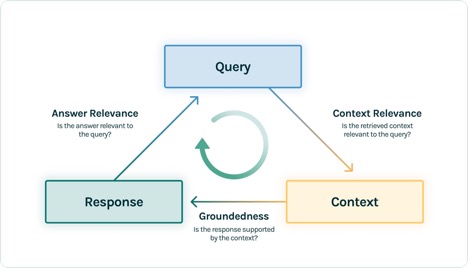
Let’s undergo every of those suggestions capabilities to grasp how they’ll profit us.
Context relevance
Context is a important enter to the standard of our utility’s responses, and it may be helpful to programmatically be sure that the context offered is related to the enter question. That is important as a result of this context shall be utilized by the LLM to type a solution, so any irrelevant info within the context may very well be weaved right into a hallucination. TruLens allows you to consider context relevance through the use of the construction of the serialized report:
As a result of the context offered to LLMs is essentially the most consequential step of a Retrieval Augmented Era (RAG) pipeline, context relevance is important for understanding the standard of retrievals. Working with prospects throughout sectors, we’ve seen quite a lot of failure modes recognized utilizing this analysis, reminiscent of incomplete context, extraneous irrelevant context, and even lack of enough context out there. By figuring out the character of those failure modes, our customers are capable of adapt their indexing (reminiscent of embedding mannequin and chunking) and retrieval methods (reminiscent of sentence windowing and automerging) to mitigate these points.
Groundedness
After the context is retrieved, it’s then shaped into a solution by an LLM. LLMs are sometimes vulnerable to stray from the details offered, exaggerating or increasing to a correct-sounding reply. To confirm the groundedness of the appliance, you must separate the response into separate statements and independently seek for proof that helps every throughout the retrieved context.
Points with groundedness can usually be a downstream impact of context relevance. When the LLM lacks enough context to type an evidence-based response, it’s extra more likely to hallucinate in its try to generate a believable response. Even in instances the place full and related context is offered, the LLM can fall into points with groundedness. Significantly, this has performed out in functions the place the LLM responds in a selected model or is getting used to finish a activity it’s not properly fitted to. Groundedness evaluations permit TruLens customers to interrupt down LLM responses declare by declare to grasp the place the LLM is most frequently hallucinating. Doing so has proven to be significantly helpful for illuminating the best way ahead in eliminating hallucination by way of model-side modifications (reminiscent of prompting, mannequin alternative, and mannequin parameters).
Reply relevance
Lastly, the response nonetheless must helpfully reply the unique query. You may confirm this by evaluating the relevance of the ultimate response to the person enter:
By reaching passable evaluations for this triad, you may make a nuanced assertion about your utility’s correctness; this utility is verified to be hallucination free as much as the restrict of its information base. In different phrases, if the vector database incorporates solely correct info, then the solutions offered by the context-enabled query answering app are additionally correct.
Floor reality analysis
Along with these suggestions capabilities for detecting hallucination, we now have a take a look at dataset, DataBricks-Dolly-15k, that permits us so as to add floor reality similarity as a fourth analysis metric. See the next code:
Construct the appliance
After you’ve gotten arrange your evaluators, you’ll be able to construct your utility. On this instance, we use a context-enabled QA utility. On this utility, present the instruction and context to the completion engine:
After you’ve gotten created the app and suggestions capabilities, it’s easy to create a wrapped utility with TruLens. This wrapped utility, which we title base_recorder, will log and consider the appliance every time it’s known as:
Outcomes with base Llama-2
After you’ve gotten run the appliance on every report within the take a look at dataset, you’ll be able to view the leads to your SageMaker pocket book with tru.get_leaderboard(). The next screenshot exhibits the outcomes of the analysis. Reply relevance is alarmingly low, indicating that the mannequin is struggling to persistently observe the directions offered.

Wonderful-tune Llama-2 utilizing SageMaker Jumpstart
Steps to fantastic tune Llama-2 mannequin utilizing SageMaker Jumpstart are additionally offered on this pocket book.
To arrange for fine-tuning, you first have to obtain the coaching set and setup a template for directions
Then, add each the dataset and directions to an Amazon Easy Storage Service (Amazon S3) bucket for coaching:
To fine-tune in SageMaker, you should use the SageMaker JumpStart Estimator. We largely use default hyperparameters right here, besides we set instruction tuning to true:
After you’ve gotten educated the mannequin, you’ll be able to deploy it and create your utility simply as you probably did earlier than:
Consider the fine-tuned mannequin
You may run the mannequin once more in your take a look at set and examine the outcomes, this time compared to the bottom Llama-2:

The brand new, fine-tuned Llama-2 mannequin has massively improved on reply relevance and groundedness, together with similarity to the bottom reality take a look at set. This huge enchancment in high quality comes on the expense of a slight enhance in latency. This enhance in latency is a direct results of the fine-tuning rising the scale of the mannequin.
Not solely are you able to view these leads to the pocket book, however you can too discover the leads to the TruLens UI by working tru.run_dashboard(). Doing so can present the identical aggregated outcomes on the leaderboard web page, but additionally provides you the power to dive deeper into problematic information and determine failure modes of the appliance.
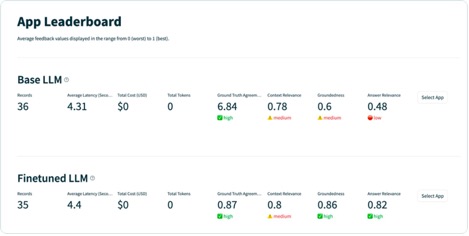
To grasp the development to the app on a report stage, you’ll be able to transfer to the evaluations web page and study the suggestions scores on a extra granular stage.
For instance, in case you ask the bottom LLM the query “What’s the strongest Porsche flat six engine,” the mannequin hallucinates the next.

Moreover, you’ll be able to study the programmatic analysis of this report to grasp the appliance’s efficiency in opposition to every of the suggestions capabilities you’ve gotten outlined. By inspecting the groundedness suggestions leads to TruLens, you’ll be able to see an in depth breakdown of the proof out there to help every declare being made by the LLM.

If you happen to export the identical report to your fine-tuned LLM in TruLens, you’ll be able to see that fine-tuning with SageMaker JumpStart dramatically improved the groundedness of the response.

By utilizing an automatic analysis workflow with TruLens, you’ll be able to measure your utility throughout a wider set of metrics to raised perceive its efficiency. Importantly, you at the moment are capable of perceive this efficiency dynamically for any use case—even these the place you haven’t collected floor reality.
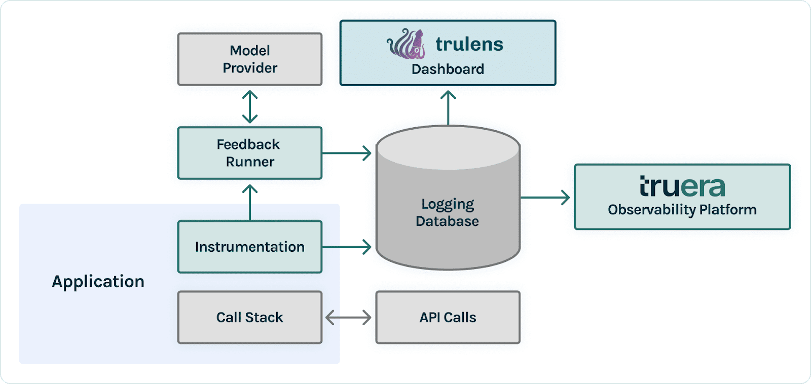
How TruLens works
After you’ve gotten prototyped your LLM utility, you’ll be able to combine TruLens (proven earlier) to instrument its name stack. After the decision stack is instrumented, it might then be logged on every run to a logging database residing in your setting.
Along with the instrumentation and logging capabilities, analysis is a core part of worth for TruLens customers. These evaluations are applied in TruLens by suggestions capabilities to run on prime of your instrumented name stack, and in flip name upon exterior mannequin suppliers to supply the suggestions itself.
After suggestions inference, the suggestions outcomes are written to the logging database, from which you’ll run the TruLens dashboard. The TruLens dashboard, working in your setting, lets you discover, iterate, and debug your LLM app.
At scale, these logs and evaluations will be pushed to TruEra for manufacturing observability that may course of hundreds of thousands of observations a minute. By utilizing the TruEra Observability Platform, you’ll be able to quickly detect hallucination and different efficiency points, and zoom in to a single report in seconds with built-in diagnostics. Shifting to a diagnostics viewpoint lets you simply determine and mitigate failure modes to your LLM app reminiscent of hallucination, poor retrieval high quality, questions of safety, and extra.
Consider for trustworthy, innocent, and useful responses
By reaching passable evaluations for this triad, you’ll be able to attain the next diploma of confidence within the truthfulness of responses it offers. Past truthfulness, TruLens has broad help for the evaluations wanted to grasp your LLM’s efficiency on the axis of “Trustworthy, Innocent, and Useful.” Our customers have benefited tremendously from the power to determine not solely hallucination as we mentioned earlier, but additionally points with security, safety, language match, coherence, and extra. These are all messy, real-world issues that LLM app builders face, and will be recognized out of the field with TruLens.

Conclusion
This submit mentioned how one can speed up the productionisation of AI functions and use basis fashions in your group. With SageMaker JumpStart, Amazon Bedrock, and TruEra, you’ll be able to deploy, fine-tune, and iterate on basis fashions to your LLM utility. Checkout this hyperlink to seek out out extra about TruEra and check out the pocket book your self.
In regards to the authors
 Josh Reini is a core contributor to open-source TruLens and the founding Developer Relations Knowledge Scientist at TruEra the place he’s liable for training initiatives and nurturing a thriving neighborhood of AI High quality practitioners.
Josh Reini is a core contributor to open-source TruLens and the founding Developer Relations Knowledge Scientist at TruEra the place he’s liable for training initiatives and nurturing a thriving neighborhood of AI High quality practitioners.
 Shayak Sen is the CTO & Co-Founding father of TruEra. Shayak is concentrated on constructing programs and main analysis to make machine studying programs extra explainable, privateness compliant, and truthful.
Shayak Sen is the CTO & Co-Founding father of TruEra. Shayak is concentrated on constructing programs and main analysis to make machine studying programs extra explainable, privateness compliant, and truthful.
 Anupam Datta is Co-Founder, President, and Chief Scientist of TruEra. Earlier than TruEra, he spent 15 years on the school at Carnegie Mellon College (2007-22), most just lately as a tenured Professor of Electrical & Laptop Engineering and Laptop Science.
Anupam Datta is Co-Founder, President, and Chief Scientist of TruEra. Earlier than TruEra, he spent 15 years on the school at Carnegie Mellon College (2007-22), most just lately as a tenured Professor of Electrical & Laptop Engineering and Laptop Science.
![]() Vivek Gangasani is a AI/ML Startup Options Architect for Generative AI startups at AWS. He helps rising GenAI startups construct modern options utilizing AWS companies and accelerated compute. At the moment, he’s centered on creating methods for fine-tuning and optimizing the inference efficiency of Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures and attempting completely different cuisines.
Vivek Gangasani is a AI/ML Startup Options Architect for Generative AI startups at AWS. He helps rising GenAI startups construct modern options utilizing AWS companies and accelerated compute. At the moment, he’s centered on creating methods for fine-tuning and optimizing the inference efficiency of Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures and attempting completely different cuisines.

{kind=link}