
Apache Cassandra clearly can’t inform the long run. It may well solely allow you to arrange information storage (or at the very least make it as organized as it will possibly get in a distributed system). However how good is Cassandra at it? Discover all of the wanted particulars beneath in order that Cassandra efficiency shouldn’t be all Greek to you anymore.

Phrases you might not know but
Down beneath, our Cassandra specialists use various particular phrases that you could be encounter for the primary time. Right here, you might discover all these phrases briefly defined.
Token is a considerably summary quantity assigned to each node of the cluster in an ascending method. All of the nodes kind a token ring.
Partitioner is the algorithm that decides what nodes within the cluster are going to retailer information.
Replication issue determines the variety of information replicas.
Keyspace is the worldwide space for storing that accommodates all column households of 1 utility.
Column household is a set of Cassandra’s minimal items of knowledge storage (columns). Columns include a column title (key), a price and a timestamp.
Memtable is a cache reminiscence construction.
SSTable is an unchangeable information construction created as quickly as a memtable is flushed onto a disk.
Major index is part of the SSTable that has a set of this desk’s row keys and factors to the keys’ location within the given SSTable.
Major key in Cassandra consists of a partition key and a lot of clustering columns (if any). The partition key helps to know what node shops the info, whereas the clustering columns manage information within the desk in ascending alphabetical order (often).
Bloom filters are information buildings used to shortly discover which SSTables are more likely to have the wanted information.
Secondary index can find information inside a single node by its non-primary-key columns. SASI (SSTable Connected Secondary Index) is an improved model of a secondary index ‘affixed’ to SSTables.
Materialized view is a way of ‘cluster-wide’ indexing that creates one other variant of the bottom desk however contains the queried columns into the partition key (whereas with a secondary index, they’re ignored of it). This manner, it’s attainable to seek for listed information throughout the entire cluster with out wanting into each node.
Knowledge modeling in Cassandra
Cassandra’s efficiency is very depending on the way in which the info mannequin is designed. So, earlier than you dive into it, just remember to perceive Cassandra’s three information modeling ‘dogmas’:
- Disk house is reasonable.
- Writes are low cost.
- Community communication is pricey.
These three statements reveal the true sense behind all Cassandra’s peculiarities described within the article.
And as to a very powerful guidelines to observe whereas designing a Cassandra information mannequin, right here they’re:
- Do unfold information evenly within the cluster, which suggests having an excellent major key.
- Do scale back the variety of partition reads, which suggests first desirous about the long run queries’ composition earlier than modeling the info.
Knowledge partitioning and denormalization
To evaluate Cassandra efficiency, it’s logical to begin at first of knowledge’s path and first take a look at its effectivity whereas distributing and duplicating information.
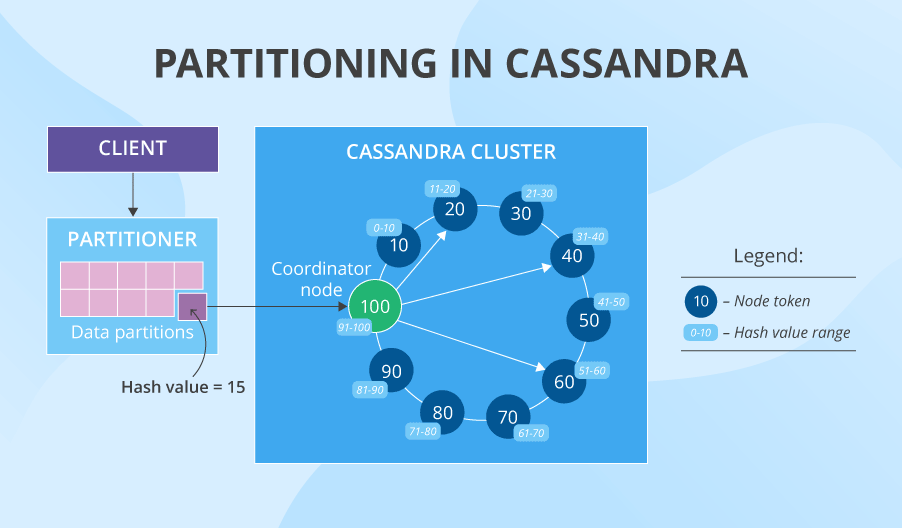
Partitioning and denormalization: The course of
Whereas distributing information, Cassandra makes use of constant hashing and practices information replication and partitioning. Think about that we’ve got a cluster of 10 nodes with tokens 10, 20, 30, 40, and so on. A partitioner converts the info’s major key right into a sure hash worth (say, 15) after which appears to be like on the token ring. The primary node whose token is larger than the hash worth is the primary option to retailer the info. And if we’ve got the replication issue of three (often it’s 3, but it surely’s tunable for every keyspace), the following two tokens’ nodes (or those which might be bodily nearer to the primary node) additionally retailer the info. That is how we get information replicas on three separate nodes good and simple. However apart from that, Cassandra additionally practices denormalization and encourages information duplication: creating quite a few variations of 1 and the identical desk optimized for various learn requests. Think about how a lot information it’s, if we’ve got the identical enormous denormalized desk with repeating information on 3 nodes and every of the nodes additionally has at the very least 3 variations of this desk.
Partitioning and denormalization: The draw back
The truth that information is denormalized in Cassandra could seem bizarre, in case you come from a relational-database background. When any non-big-data system scales up, it’s good to do issues like learn replication, sharding and index optimization. However sooner or later, your system turns into virtually inoperable, and also you understand that the wonderful relational mannequin with all its joins and normalization is the precise cause for efficiency points.
To unravel this, Cassandra has denormalization in addition to creates a number of variations of 1 desk optimized for various reads. However this ‘help’ doesn’t come with out consequence. Once you determine to extend your learn efficiency by creating information replicas and duplicated desk variations, write efficiency suffers a bit as a result of you’ll be able to’t simply write as soon as anymore. You must write the identical factor n instances. Apart from, you want an excellent mechanism of selecting which node to put in writing to, which Cassandra gives, so no blames right here. And though these losses to the write efficiency in Cassandra are scanty and sometimes uncared for, you continue to want the assets for a number of writes.
Partitioning and denormalization: The upside
Constant hashing could be very environment friendly for information partitioning. Why? As a result of the token ring covers the entire array of attainable keys and the info is distributed evenly amongst them with every of the nodes getting loaded roughly the identical. However probably the most nice factor about it’s that your cluster’s efficiency is virtually linearly scalable. It sounds too good to be true, however it’s in reality so. If you happen to double the variety of nodes, the gap between their tokens will lower by half and, consequently, the system will be capable to deal with virtually twice as many reads and writes. The additional bonus right here: with doubled nodes, your system turns into much more fault-tolerant.
The write
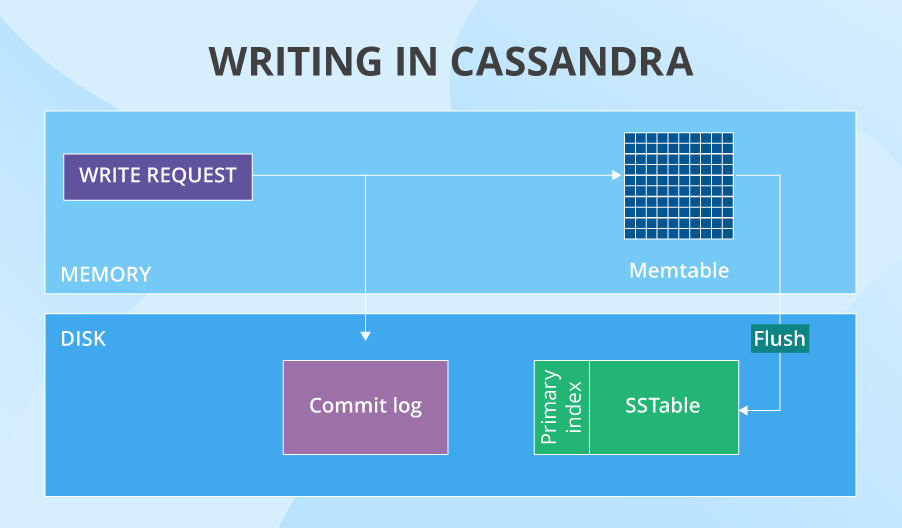
Write: The course of
After being directed to a particular node, a write request first will get to the commit log (it shops all the information about in-cache writes). On the similar time, the info will get saved within the memtable. In some unspecified time in the future (for example, when the memtable is full), Cassandra flushes the info from cache onto the disk – into SSTables. On the similar second, the commit log purges all its information, because it now not has to be careful for the corresponding information in cache. After a node writes the info, it notifies the coordinator node concerning the efficiently accomplished operation. And the variety of such success notifications is determined by the information consistency degree for writes set by your Cassandra specialists.
Such a course of occurs on all nodes that get to put in writing a partition. However what if one in all them is down? There’s a sublime resolution for it – hinted handoff. When the coordinator sees {that a} reproduction node shouldn’t be responding, it shops the missed write. Then, Cassandra briefly creates within the native keyspace a touch that can later remind the ‘derailed’ node to put in writing sure information after it goes again up. If the node doesn’t recuperate inside 3 hours, the coordinator shops the write completely.
Write: The draw back
Nonetheless, the write shouldn’t be excellent. Right here’re some upsetting issues:
- Append operations work simply superb, whereas updates are conceptually lacking in Cassandra (though it’s not totally proper to say so, since such a command exists). When it’s good to replace a sure worth, you simply add an entry with the identical major key however a brand new worth and a youthful timestamp. Simply think about what number of updates you might want and the way a lot house that can take up. Furthermore, it will possibly have an effect on learn efficiency, since Cassandra might want to look by means of a number of information on a single key and test whichever the latest one is. Nonetheless, every now and then, compaction is enacted to merge such information and unlock house.
- The hinted handoff course of can overload the coordinator node. If this occurs, the coordinator will refuse writes, which may end up in the lack of some information replicas.
Write: The upside
Cassandra’s write efficiency remains to be fairly good, although. Right here’s why:
- Cassandra avoids random information enter having a transparent state of affairs for the way issues go, which contributes to the write efficiency.
- To make it possible for all of the chosen nodes do write the info, even when a few of them are down, there’s the above-mentioned hinted handoff course of. Nonetheless, it’s best to observe that hinted handoff solely works when your consistency degree is met.
- The design of the write operation entails the commit log, which is sweet. Why? If a node goes down, replaying the commit log after it’s up once more will restore all of the misplaced in-cache writes to the memtable.
The learn
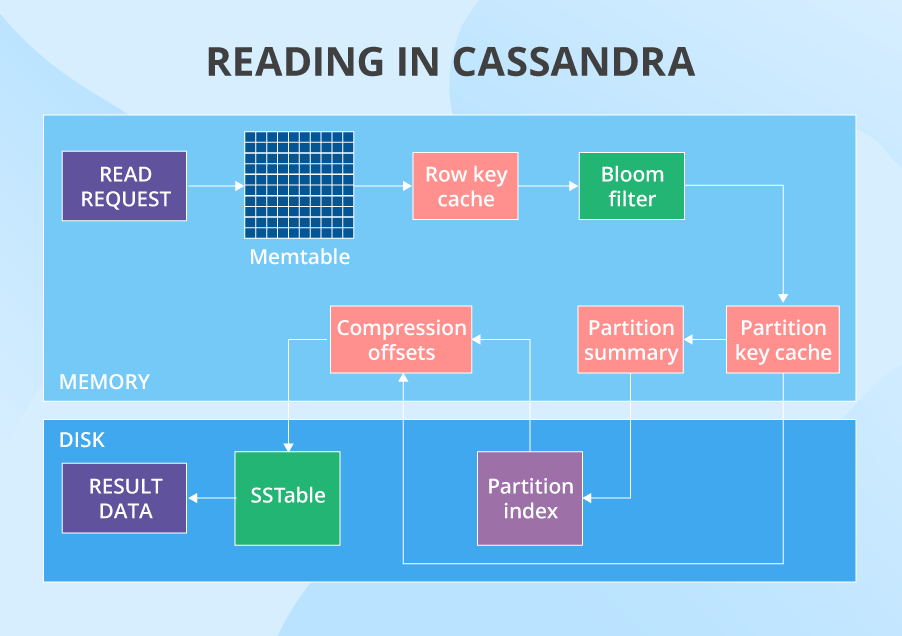
Learn: The course of
When a learn request begins its journey, the info’s partition secret’s used to search out what nodes have the info. After that, the request is shipped to a lot of nodes set by the tunable consistency degree for reads. Then, on every node, in a sure order, Cassandra checks totally different locations that may have the info. The primary one is the memtable. If the info shouldn’t be there, it checks the row key cache (if enabled), then the bloom filter after which the partition key cache (additionally if enabled). If the partition key cache has the wanted partition key, Cassandra goes straight to the compression offsets, and after that it lastly fetches the wanted information out of a sure SSTable. If the partition key wasn’t present in partition key cache, Cassandra checks the partition abstract after which the major index earlier than going to the compression offsets and extracting the info from the SSTable.
After the info with the newest timestamp is positioned, it’s fetched to the coordinator. Right here, one other stage of the learn happens. As we’ve acknowledged right here, Cassandra has points with information consistency. The factor is that you simply write many information replicas, and you might learn their outdated variations as an alternative of the newer ones. However Cassandra doesn’t ignore these consistency-related issues: it tries to unravel them with a learn restore course of. The nodes which might be concerned within the learn return outcomes. Then, Cassandra compares these outcomes primarily based on the “final write wins” coverage. Therefore, the brand new information model is the primary candidate to be returned to the person, whereas the older variations are rewritten to their nodes. However that’s not all. Within the background, Cassandra checks the remainder of the nodes which have the requested information (as a result of the replication issue is usually larger than consistency degree). When these nodes return outcomes, the DB additionally compares them and the older ones get rewritten. Solely after this, the person truly will get the end result.
Learn: The draw back
Cassandra learn efficiency does get pleasure from quite a lot of glory, but it surely’s nonetheless not totally flawless.
- All is ok so long as you solely question your information by the partition key. If you wish to do it by an out-of-the-partition-key column (use a secondary index or a SASI), issues can go downhill. The issue is that secondary indexes and SASIs don’t include the partition key, which suggests there’s no method to know what node shops the listed information. It leads to looking for the info on all nodes within the cluster, which is neither low cost nor fast.
- Each the secondary index and the SASI aren’t good for top cardinality columns (in addition to for counter and static columns). Utilizing these indexes on the ‘uncommon’ information can considerably lower learn efficiency.
- Bloom filters are primarily based on probabilistic algorithms and are supposed to convey up outcomes very quick. This typically results in false positives, which is one other method to waste time and assets whereas looking out within the fallacious locations.
- Aside from the learn, secondary indexes, SASIs and materialized views can adversely have an effect on the write. In case with SASI and secondary index, each time information is written to the desk with an listed column, the column households that include indexes and their values should be up to date. And in case with materialized views, if something new is written to the bottom desk, the materialized view itself should be modified.
- If it’s good to learn a desk with hundreds of columns, you’ll have issues. Cassandra has limitations relating to the partition dimension and variety of values: 100 MB and a pair of billion respectively. So in case your desk accommodates too many columns, values or is just too large in dimension, you received’t be capable to learn it shortly. And even received’t be capable to learn it in any respect. And that is one thing to bear in mind. If the duty doesn’t strictly require studying this variety of columns, it’s at all times higher to separate such tables into a number of items. Apart from, it’s best to keep in mind that the extra columns the desk has, the extra RAM you’ll have to learn it.
Learn: The upside
Concern not, there are robust sides to the learn efficiency as properly.
- Cassandra gives excitingly regular information availability. It would not have a single level of failure, plus, it has information saved on quite a few nodes and in quite a few locations. So, if a number of nodes are down (as much as half the cluster), you’ll learn your information anyway (offered that your replication issue is tuned accordingly).
- The consistency issues might be solved in Cassandra by means of the intelligent and quick learn restore course of. It’s fairly environment friendly and really useful, however nonetheless we will’t say it really works completely on a regular basis.
- You might assume that the learn course of is just too lengthy and that it checks too many locations, which is inefficient relating to querying regularly accessed information. However Cassandra has an extra shortened learn course of for the often-needed information. For such instances, the info itself might be saved in a row cache. Or its ‘tackle’ might be in the important thing cache, which facilitates the method so much.
- Secondary indexes can nonetheless be helpful, if we’re talking about analytical queries, when it’s good to entry all or virtually all nodes anyway.
- SASIs might be a particularly good software for conducting full textual content searches.
- The mere existence of materialized views might be seen as a bonus, since they will let you simply discover wanted listed columns within the cluster. Though creating extra variants of tables will take up house.
Cassandra efficiency: Conclusion
Summarizing Cassandra efficiency, let’s take a look at its major upside and draw back factors. Upside: Cassandra distributes information effectively, permits virtually linear scalability, writes information quick and gives virtually fixed information availability. Draw back: information consistency points aren’t a rarity and indexing is much from excellent.
Clearly, no person’s with out sin, and Cassandra shouldn’t be an exception. Some points can certainly affect write or learn efficiency enormously. So, you have to to consider Cassandra efficiency tuning in case you encounter write or learn inefficiencies, and that may contain something from barely tweaking your replication elements or consistency ranges to a whole information mannequin redesign. However this under no circumstances implies that Cassandra is a low-performance product. If in contrast with MongoDB and HBase on its efficiency beneath combined operational and analytical workload, Cassandra – with all its hindrances – is by far the very best out of the three (which solely proves that the NoSQL world is a extremely good distance from excellent). Nonetheless, Cassandra’s excessive efficiency relies upon so much on the experience of the workers that offers along with your Cassandra clusters. So, in case you select Cassandra, good job! Now, select the appropriate individuals to work with it.

Cassandra Consulting and Assist
Really feel helpless being left alone along with your Cassandra points? Hit the button, and we’ll offer you all the assistance it’s good to deal with Cassandra troubles.

{kind=link}