
Apache Cassandra and Apache HBase are very like two strangers whom you meet on the street and suppose to be twins. You don’t actually know them, however their comparable peak, garments and hairstyles make you see no variations between them. Nonetheless, after having a more in-depth look, you understand that these two appeared an identical solely at a distance.
Having quite a few similarities, like being NoSQL wide-column shops and descending from BigTable, Cassandra and HBase do differ. As an example, HBase doesn’t have a question language, which implies that you’ll should work with JRuby-based HBase shell and contain further applied sciences like Apache Hive, Apache Drill or one thing of the type. Whereas Cassandra can boast its personal CQL (Cassandra Question Language), which Cassandra specialists discover most useful.
1. Information mannequin
HBase
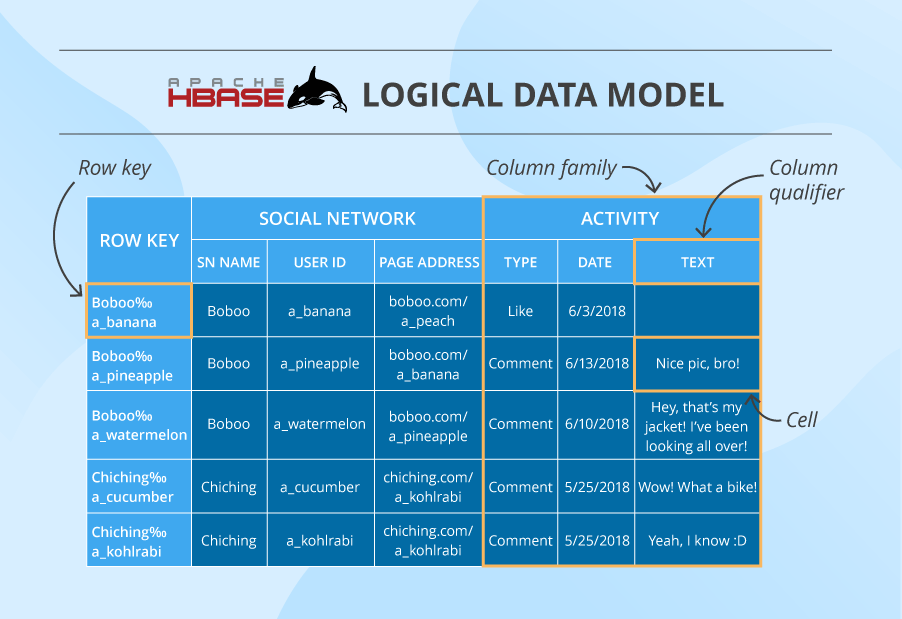
Right here now we have a desk that consists of cells organized by row keys and column households. Generally, a column household (CF) has numerous column qualifiers to assist higher arrange knowledge inside a CF.
A cell comprises a worth and a timestamp. And a column is a set of cells below a typical column qualifier and a typical CF.
Inside a desk, knowledge is partitioned by 1-column row key in lexicographical order, the place topically associated knowledge is saved shut collectively to maximise efficiency. The design of the row key’s essential and needs to be completely thought by within the algorithm written by the developer to make sure environment friendly knowledge lookups.
Cassandra
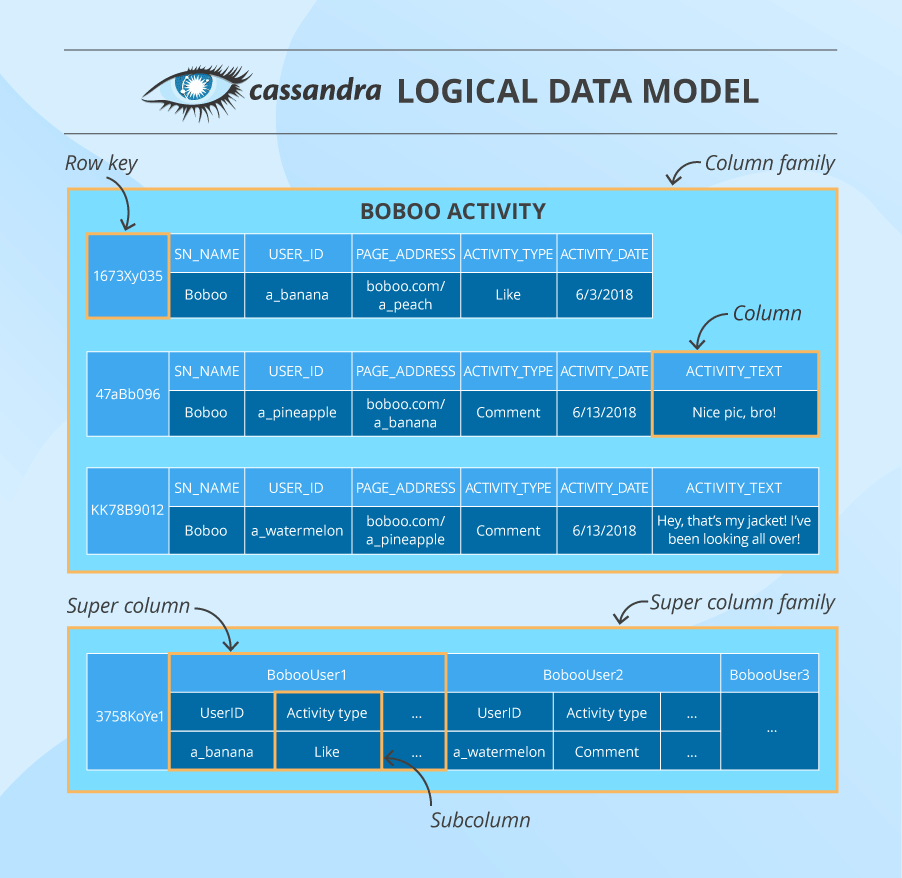
Right here now we have a column household that consists of columns organized by row keys. A column comprises a identify/key, a worth and a timestamp. Along with a typical column, Cassandra additionally has tremendous columns containing two or extra subcolumns. Such models are grouped into tremendous column households (though these are not often used).
Within the cluster, knowledge is partitioned by a multi-column main key that will get a hash worth and is shipped to the node whose token is numerically larger than the hash worth. In addition to that, the info can also be written to a further variety of nodes that will depend on the replication issue set by Cassandra practitioners. The selection of extra nodes might depend upon their bodily location within the cluster.
HBase vs. Cassandra (knowledge mannequin comparability)
The phrases are nearly the identical, however their meanings are completely different. Beginning with a column: Cassandra’s column is extra like a cell in HBase. A column household in Cassandra is extra like an HBase desk. And the column qualifier in HBase reminds of a tremendous column in Cassandra, however the latter comprises no less than 2 subcolumns, whereas the previous – just one.
In addition to, Cassandra permits for a main key to comprise a number of columns and HBase, in contrast to Cassandra, has solely 1-column row key and lays the burden of row key design on the developer. Additionally, Cassandra’s main key include a partition key and clustering columns, the place the partition key can also comprise a number of columns.
Regardless of these ‘conflicts,’ the that means of each knowledge fashions is just about the identical. They haven’t any joins, which is why they group topically associated knowledge collectively. They each can haven’t any worth in a sure cell/column, which takes up no space for storing. They each have to have column households specified whereas schema design and may’t change them afterwards, whereas permitting for columns’ or column qualifiers’ flexibility at any time. However, most significantly, they each are good for storing massive knowledge.
2. Structure
Cassandra has a masterless structure, whereas HBase has a master-based one. This is similar architectural distinction as between Cassandra and HDFS.
Which means that HBase has a single level of failure, whereas Cassandra doesn’t. An HBase consumer does talk immediately with the slave-server with out contacting the grasp, which provides the cluster some working time after the grasp goes down. However, this could hardly compete with the always-available Cassandra cluster. So, in the event you can’t afford any downtimes, Cassandra is your alternative.
Nonetheless, to make sure availability, Cassandra replicates and duplicates knowledge, which ends up in knowledge consistency issues. This makes Cassandra a foul alternative in case your resolution relies upon closely on knowledge consistency, in contrast to the strongly constant HBase. As a result of the latter writes knowledge solely to at least one place and all the time is aware of the place to search out it (knowledge replication is finished ‘externally’ in HDFS).
In addition to, Cassandra’s structure helps each knowledge administration and storage, whereas HBase’s structure is designed for knowledge administration solely. By its nature, HBase depends closely on different applied sciences, similar to HDFS for storage, Apache Zookeeper for server standing administration and metadata. And once more, it wants further applied sciences to run queries.
3. Efficiency
Cassandra’s and HBase’s on-server write paths are very a lot alike. There’re solely slight variations: names for knowledge buildings and the truth that, in contrast to Cassandra, HBase doesn’t write to the log and cache concurrently (it makes writes slower).
On the upper architectural degree, HBase has much more disadvantages:
- Earlier than attending to the wanted server, the consumer has to ‘ask’ Zookeeper which server has the hbase:meta desk containing information about all tables’ areas within the cluster. Then, the consumer asks the meta-table-holding server ‘who’ shops the precise desk it wants to put in writing to. And solely after that the consumer writes the info to the wanted place. If such writes (and in addition reads) are frequent, this information is after all cached. But when a desk area is moved to a different server, the consumer must do the total spherical once more. Whereas Cassandra’s knowledge distribution and partitioning based mostly on constant hashing is far cleverer and faster than that.
- As quickly because the in-HBase write path ends (cached knowledge will get flushed to the disk), HDFS additionally wants time to bodily retailer the info.
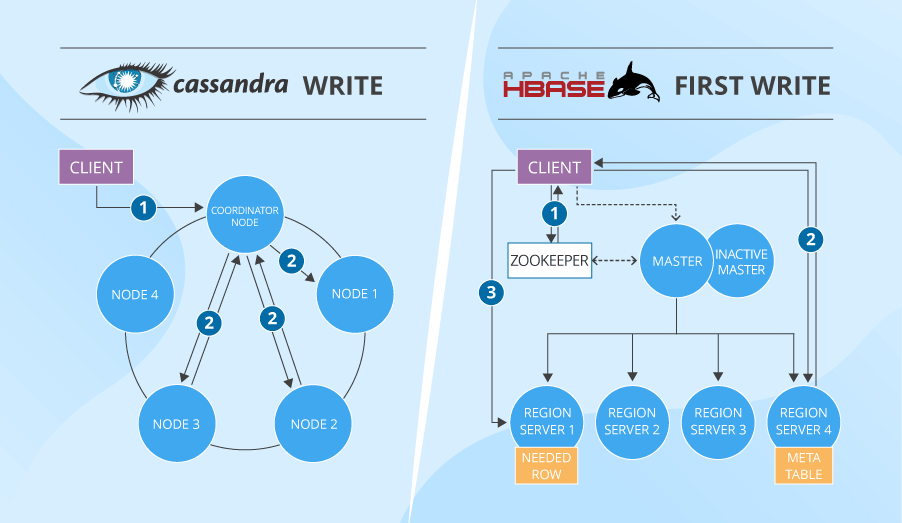
Furthermore, the precise measurements of Cassandra’s write efficiency (in a 32-node cluster, nearly 326,500 operations per second versus HBase’s 297,000) additionally show that Cassandra is healthier at writes than HBase.
In case you want plenty of quick and constant reads (random entry to knowledge and scans), then you may go for HBase. It writes solely on one server, so there is no such thing as a want to check completely different nodes’ knowledge variations. HBase servers additionally don’t have too many knowledge buildings to verify earlier than discovering your knowledge. You could suppose that HBase’s learn is inefficient for the reason that knowledge is definitely saved in HDFS, and HBase must get it out of there each time. However HBase has a block cache that has all ceaselessly accessed HDFS knowledge, plus bloom filters with all different knowledge’s approximate ‘addresses,’ which accelerates knowledge retrieval. Primarily, HBase and HDFS’s index system is multi-layered, which is rather more environment friendly than Cassandra’s indexes (take a look at our article on Cassandra efficiency to search out out extra about reads).
In case you’ve learn that Cassandra can also be excellent at reads, you could be bewildered by the conclusion that HBase is healthier. Particularly in the event you noticed this benchmarking expertise the place Cassandra handles 129,000 reads per second towards HBase’s simply 8,000 (in a 32-node cluster). The factor is, these reads are focused (based mostly on recognized main keys) and, chances are high, they’re additionally fairly inconsistent. So, Cassandra’s big numbers fade, if we’re talking about scans and consistency.
4. Safety
Like all NoSQL databases, HBase and Cassandra have their safety points (the principle one being that securing knowledge spoils efficiency making the system heavy and rigid). But it surely’s protected to say that each databases have some options to make sure knowledge safety: authentication and authorization in each and inter-node + client-to-node encryption in Cassandra. HBase, in its flip, offers the much-needed means for safe communication with different applied sciences it depends upon.
A bit extra element:
Each Cassandra and HBase present not simply database-wide entry management however enable a sure degree of granularity. Cassandra permits row-level entry and HBase goes as deep as cell-level. Cassandra defines consumer roles and units circumstances for these roles which later decide whether or not a consumer can see explicit knowledge or not. Whereas HBase has an inverse ‘transfer.’ Its directors assign a visibility label to knowledge units after which ‘inform’ customers and consumer teams what labels they will see.
5. Software areas
Judging by how Cassandra and HBase arrange their knowledge fashions, they’re each actually good with time-series knowledge: sensor readings in IoT methods, web site visits and buyer habits, inventory trade knowledge, and so forth. They each retailer and browse such values properly. In addition to that, scalability is the property they each have: Cassandra – linear, HBase – linear and modular ones.
Nonetheless, with regards to scanning big volumes of information to discover a small variety of outcomes, as a result of having no knowledge duplications, HBase is healthier. As an example, this motive applies to HBase’s means to deal with textual content evaluation (based mostly on internet pages, social community posts, dictionaries and so forth). Plus, HBase can do effectively with knowledge administration platforms and primary knowledge evaluation (counting, summing and such; as a result of its coprocessors in Java).
Cassandra is nice for big volumes of knowledge ingestion, because it’s an environment friendly write-oriented database. With it, you’ll construct a dependable and obtainable knowledge retailer. As well as, Cassandra lets you create knowledge facilities in numerous international locations and preserve them working in sync. In addition to, in the event you couple Cassandra with Spark, you may also obtain good scan efficiency.
However the principle distinction between making use of Cassandra and HBase in actual tasks is that this. Cassandra is nice for ‘always-on’ internet or cellular apps and tasks with advanced and/or real-time analytics. But when there’s no rush for evaluation outcomes (for example, doing knowledge lake experiments or creating machine studying fashions), HBase could also be a sensible choice. Particularly in the event you’ve already invested in Hadoop infrastructure and talent set.
Cassandra vs. HBase – a recap
Cassandra is a ‘self-sufficient’ expertise for knowledge storage and administration, whereas HBase just isn’t. The latter was supposed as a instrument for random knowledge enter/output for HDFS, which is why all its knowledge is saved there. In addition to, HBase makes use of Zookeeper as a server standing supervisor and the ‘guru’ that is aware of the place all metadata is (to keep away from quick cluster failures, when the metadata-containing grasp goes down). Consequently, HBase’s advanced interdependent system is tougher to configure, safe and preserve.
Cassandra is nice at writes, whereas HBase is nice at intensive reads. Cassandra’s weak spot is knowledge consistency, whereas HBase’s ache is knowledge availability, though each attempt to mitigate the antagonistic penalties of those issues. Additionally, each don’t stand frequent knowledge deletes and updates.
So, Cassandra and HBase are positively not twins however simply two strangers with an identical coiffure. To decide on between the 2, you must completely analyze your duties. After which, attempt to discover a option to strengthen the database’s weak spots with out affecting its efficiency.

Want skilled recommendation on massive knowledge and devoted applied sciences? Get it from ScienceSoft, massive knowledge experience since 2013.

{kind=link}